The XML C parser and toolkit of Gnome
Note: this is the flat content of the website
libxml, a.k.a. gnome-xml
"Programmingwithlibxml2
is like the thrilling embrace of an exotic stranger." MarkPilgrim
Libxml2 is the XML C parser and toolkit developed for the Gnomeproject(but
usable outside of the Gnome platform), it is free softwareavailableunder the
MITLicense.XML
itself is a metalanguage to design markup languages, i.e.text languagewhere
semantic and structure are added to the content usingextra
"markup"information enclosed between angle brackets. HTML is the
mostwell-knownmarkup language. Though the library is written in C avariety of language bindingsmake it available inother
environments.
Libxml2 is known to be very portable, the library should build
andworkwithout serious troubles on a variety of systems (Linux,
Unix,Windows,CygWin, MacOS, MacOS X, RISC Os, OS/2, VMS, QNX, MVS, ...)
Libxml2 implements a number of existing standards related
tomarkuplanguages:
In most cases libxml2 tries to implement the specifications in
arelativelystrictly compliant way. As of release 2.4.16, libxml2 passed
all1800+ testsfrom the OASIS
XMLTestsSuite.
To some extent libxml2 provides support for the
followingadditionalspecifications but doesn't claim to implement them
completely:
- Document Object Model (DOM) http://www.w3.org/TR/DOM-Level-2-Core/thedocument
model, but it doesn't implement the API itself, gdome2 doesthison top of
libxml2
- RFC959:libxml2
implements a basic FTP client code
- RFC1945:HTTP/1.0,
again a basic HTTP client code
- SAX: a SAX2 like interface and a minimal SAX1
implementationcompatiblewith early expat versions
A partial implementation of XML Schemas
Part1:Structureis being worked on but it would be far too early to
makeanyconformance statement about it at the moment.
Separate documents:
Logo designed by Marc Liyanage.
This document describes libxml, the XMLC parser and toolkit developed for theGnomeproject. XML is a standardfor
buildingtag-basedstructured documents/data.
Here are some key points about libxml:
- Libxml2 exports Push (progressive) and Pull (blocking)
typeparserinterfaces for both XML and HTML.
- Libxml2 can do DTD validation at parse time, using a
parseddocumentinstance, or with an arbitrary DTD.
- Libxml2 includes complete XPath, XPointerand XIncludeimplementations.
- It is written in plain C, making as few assumptions as
possible,andsticking closely to ANSI C/POSIX for easy embedding.
WorksonLinux/Unix/Windows, ported to a number of other platforms.
- Basic support for HTTP and FTP client allowing applications
tofetchremote resources.
- The design is modular, most of the extensions can be compiled out.
- The internal document representation is as close as possible to the DOMinterfaces.
- Libxml2 also has a SAX like
interface;theinterface is designed to be compatible with Expat.
- This library is released under the MITLicense.See
the Copyright file in the distribution for the precisewording.
Warning: unless you are forced to because your application links
withaGnome-1.X library requiring it, Do Not Use
libxml1,uselibxml2
Table of Contents:
- Licensing Terms for libxml
libxml2 is released under the MITLicense;see
the file Copyright in the distribution for the precisewording
- Can I embed libxml2 in a proprietary application ?
Yes. The MIT License allows you to keep proprietary the changesyoumade
to libxml, but it would be graceful to send-back bug fixesandimprovements
as patches for possible incorporation in themaindevelopment tree.
- Do
NotUselibxml1, use libxml2
- Where can I get libxml?
The original distribution comes from xmlsoft.orgor gnome.org
Most Linux and BSD distributions include libxml, this is
probablythesafer way for end-users to use libxml.
David Doolin provides precompiled Windows versions at http://www.ce.berkeley.edu/~doolin/code/libxmlwin32/
- I see libxml and libxml2 releases, which one should I install ?
- If you are not constrained by backward compatibility
issueswithexisting applications, install libxml2 only
- If you are not doing development, you can safely
installboth.Usually the packages libxmland libxml2arecompatible(this
is not the case for development packages).
- If you are a developer and your system provides
separatepackagingfor shared libraries and the development components,
it ispossibleto install libxml and libxml2, and also libxml-develandlibxml2-develtoofor
libxml2 >= 2.3.0
- If you are developing a new application, please
developagainstlibxml2(-devel)
- I can't install the libxml package, it conflicts with libxml0
You probably have an old libxml0 package used to provide
thesharedlibrary for libxml.so.0, you can probably safely remove it.
Thelibxmlpackages provided on xmlsoft.orgprovidelibxml.so.0
- I can't install the libxml(2) RPM package due
tofaileddependencies
The most generic solution is to re-fetch the latest src.rpm
,andrebuild it locally with
rpm --rebuild libxml(2)-xxx.src.rpm.
If everything goes well it will generate two binary rpm
packages(oneproviding the shared libs and xmllint, and the other one,
the-develpackage, providing includes, static libraries and scripts needed
tobuildapplications with libxml(2)) that you can install locally.
- What is the process to compile libxml2 ?
As most UNIX libraries libxml2 follows the "standard":
gunzip -c xxx.tar.gz | tar xvf -
cd libxml-xxxx
./configure --help
to see the options, then the compilation/installation proper
./configure [possible options]
make
make install
At that point you may have to rerun ldconfig or a similar
utilitytoupdate your list of installed shared libs.
- What other libraries are needed to compile/install libxml2 ?
Libxml2 does not require any other library, the normal C ANSIAPIshould
be sufficient (please report any violation to this rule youmayfind).
However if found at configuration time libxml2 will detect and
usethefollowing libs:
- libz:ahighly
portable and available widely compression library.
- iconv: a powerful character encoding conversion library.
Itisincluded by default in recent glibc libraries, so it doesn't
needtobe installed specifically on Linux. It now seems a partofthe
official UNIXspecification. Here is one implementation
ofthelibrarywhich source can be found here.
- Make check fails on some platforms
Sometimes the regression tests' results don't completely matchthevalue
produced by the parser, and the makefile uses diff to printthedelta. On
some platforms the diff return breaks the compilationprocess;if the diff
is small this is probably not a serious problem.
Sometimes (especially on Solaris) make checks fail due tolimitationsin
make. Try using GNU-make instead.
- I use the CVS version and there is no configure script
The configure script (and other Makefiles) are generated.
Usetheautogen.sh script to regenerate the configure script
andMakefiles,like:
./autogen.sh --prefix=/usr --disable-shared
- I have troubles when running make tests with gcc-3.0
It seems the initial release of gcc-3.0 has a problem withtheoptimizer
which miscompiles the URI module. Please useanothercompiler.
- Troubles compiling or linking programs using libxml2
Usually the problem comes from the fact that the compiler
doesn'tgetthe right compilation or linking flags. There is a small
shellscriptxml2-configwhich is installed as part of
libxml2usualinstall process which provides those flags. Use
xml2-config --cflags
to get the compilation flags and
xml2-config --libs
to get the linker flags. Usually this is done directly fromtheMakefile
as:
CFLAGS=`xml2-config --cflags`
LIBS=`xml2-config --libs`
- I want to install my own copy of libxml2 in my home
directoryandlink my programs against it, but it doesn't work
There are many different ways to accomplish this. Here is one waytodo
this under Linux. Suppose your home directory
is/home/user.Then:
- Create a subdirectory, let's call it
myxml
- unpack the libxml2 distribution into that subdirectory
- chdir into the unpacked
distribution(
/home/user/myxml/libxml2)
- configure the library using the
"
--prefix"switch,specifying an installation
subdirectoryin/home/user/myxml, e.g.
./configure
--prefix/home/user/myxml/xmlinst{otherconfiguration
options}
- now run
makefollowed by make install
- At this point, the installation subdirectory contains
thecomplete"private" include files, library files and binary
programfiles (e.g.xmllint), located in
/home/user/myxml/xmlinst/lib,/home/user/myxml/xmlinst/includeand
/home/user/myxml/xmlinst/bin
respectively.
- In order to use this "private" library, you should first add
ittothe beginning of your default PATH (so that your own
privateprogramfiles such as xmllint will be used instead of the
normalsystemones). To do this, the Bash command would be
export PATH=/home/user/myxml/xmlinst/bin:$PATH
- Now suppose you have a program
test1.cthat
youwouldlike to compile with your "private" library. Simply compile
itusingthe command
gcc `xml2-config --cflags --libs` -o test test.c
Note that, because your PATH has been set
with/home/user/myxml/xmlinst/binat the beginning,
thexml2-configprogram which you just installed will be used instead
ofthe systemdefault one, and this will automaticallyget
thecorrectlibraries linked with your program.
- xmlDocDump() generates output on one line.
Libxml2 will not inventspaces in the content
ofadocument since all spaces in the content of a
documentaresignificant. If you build a tree from the API
andwantindentation:
- the correct way is to generate those yourself too.
- the dangerous way is to ask libxml2 to add those blanks
toyourcontent modifying the content of your document
intheprocess. The result may not be what you expect.
ThereisNOway to guarantee that such a
modificationwon'taffect other parts of the content of your document.
See xmlKeepBlanksDefault()andxmlSaveFormatFile()
- Extra nodes in the document:
For a XML file as below:
<?xml version="1.0"?>
<PLAN xmlns="http://www.argus.ca/autotest/1.0/">
<NODE CommFlag="0"/>
<NODE CommFlag="1"/>
</PLAN>
after parsing it with
thefunctionpxmlDoc=xmlParseFile(...);
I want to the get the content of the first node (node
withtheCommFlag="0")
so I did it as following;
xmlNodePtr pnode;
pnode=pxmlDoc->children->children;
but it does not work. If I change it to
pnode=pxmlDoc->children->children->next;
then it works. Can someone explain it to me.
In XML all characters in the content of the document
aresignificantincluding blanks and formatting
linebreaks.
The extra nodes you are wondering about are just that, text
nodeswiththe formatting spaces which are part of the document but that
peopletendto forget. There is a function xmlKeepBlanksDefault()toremove
those at parse time, but that's an heuristic, and itsuse should belimited
to cases where you are certain there is nomixed-content in
thedocument.
- I get compilation errors of existing code like
whenaccessingrootor child
fieldsofnodes.
You are compiling code developed for libxml version 1 and
usingalibxml2 development environment. Either switch back to libxml v1
develoreven better fix the code to compile with libxml2 (or both) by following the instructions.
- I get compilation errors about
nonexistingxmlRootNodeorxmlChildrenNodefields.
The source code you are using has been upgradedto be able to compile with both
libxmlandlibxml2, but you need to install a more recent
version:libxml(-devel)>= 1.8.8 or libxml2(-devel) >= 2.1.0
- XPath implementation looks seriously broken
XPath implementation prior to 2.3.0 was really incomplete. Upgrade
toarecent version, there are no known bugs in the current version.
- The example provided in the web page does not compile.
It's hard to maintain the documentation in sync with
thecode<grin/> ...
Check the previous points 1/ and 2/ raised before, and
pleasesendpatches.
- Where can I get more examples and information than provided
ontheweb page?
Ideally a libxml2 book would be nice. I have no such plan ...
Butyoucan:
- check more deeply the existinggenerated doc
- have a look at the
setofexamples.
- look for examples of use for libxml2 function using the
Gnomecode.For example the following will query the full Gnome CVS
base fortheuse of the xmlAddChild()function:
http://cvs.gnome.org/lxr/search?string=xmlAddChild
This may be slow, a large hardware donation to the
gnomeprojectcould cure this :-)
- Browsethelibxml2
source, I try to write code as clean and documentedaspossible, so
looking at it may be helpful. In particular the codeofxmllint.c and
of the various testXXX.c test programs shouldprovidegood examples of
how to do things with the library.
- What about C++ ?
libxml2 is written in pure C in order to allow easy reuse on anumberof
platforms, including embedded systems. I don't intend to converttoC++.
There is however a C++ wrapper which may fulfill your needs:
- How to validate a document a posteriori ?
It is possible to validate documents which had not been
validatedatinitial parsing time or documents which have been built
fromscratchusing the API. Use the xmlValidateDtd()function.It
is also possible to simply add a DTD to an existingdocument:
xmlDocPtr doc; /* your existing document */
xmlDtdPtr dtd = xmlParseDTD(NULL, filename_of_dtd); /* parse the DTD */
dtd->name = xmlStrDup((xmlChar*)"root_name"); /* use the given root */
doc->intSubset = dtd;
if (doc->children == NULL) xmlAddChild((xmlNodePtr)doc, (xmlNodePtr)dtd);
else xmlAddPrevSibling(doc->children, (xmlNodePtr)dtd);
- So what is this funky "xmlChar" used all the time?
It is a null terminated sequence of utf-8 characters. And
onlyutf-8!You need to convert strings encoded in different ways to
utf-8beforepassing them to the API. This can be accomplished with the
iconvlibraryfor instance.
- etc ...
There are several on-line resources related to using libxml:
- Use the search engineto lookupinformation.
- Check the FAQ.
- Check the extensivedocumentationautomaticallyextracted
from code comments.
- Look at the documentation about libxmlinternationalization support.
- This page provides a global overview and someexampleson how to use libxml.
- Code examples
- John Fleck's libxml2 tutorial: htmlorpdf.
- If you need to parse large files, check the xmlReaderAPI tutorial
- James Henstridgewrote somenicedocumentationexplaining
how to use the libxml SAX interface.
- George Lebl wrote anarticlefor
IBM developerWorksabout using libxml.
- Check theTODOfile.
- Read the 1.x to 2.x upgrade
pathdescription.If you are starting a new project using libxml you
shouldreally use the2.x version.
- And don't forget to look at the mailing-list archive.
Well, bugs or missing features are always possible, and I will make
apointof fixing them in a timely fashion. The best way to report a bug is
touse theGnomebugtracking
database(make sure to use the "libxml2" module name). Ilook atreports
there regularly and it's good to have a reminder when a bugis stillopen. Be
sure to specify that the bug is for the package libxml2.
For small problems you can try to get help on IRC, the #xml
channelonirc.gnome.org (port 6667) usually have a few person subscribed which
mayhelp(but there is no garantee and if a real issue is raised it should go
onthemailing-list for archival).
There is also a mailing-list xml@gnome.orgfor libxml, with an on-line archive(old). To subscribe to this
list,pleasevisit the associatedWebpage
andfollow the instructions. Do not send code, I won'tdebug
it(but patches are really appreciated!).
Please note that with the current amount of virus and SPAM, sending
mailtothe list without being subscribed won't work. There is *far too
manybounces*(in the order of a thousand a day !) I cannot approve them
manuallyanymore.If your mail to the list bounced waiting for administrator
approval,it isLOST ! Repost it and fix the problem triggering the error. Also
pleasenotethat emails
withalegal warning asking to not copy or redistribute freely the
informationstheycontainare NOTacceptable for the
mailing-list,suchmail will as much as possible be discarded automatically,
and are lesslikelyto be answered if they made it to the list, DO
NOTpost tothe list from an email address where such legal
requirements areautomaticallyadded, get private paying support if you can't
shareinformations.
Check the following beforeposting:
- Read the FAQand usethesearch engineto get information related to
your problem.
- Make sure you are using
arecentversion, and that the problem still shows up in a
recentversion.
- Check the listarchivesto see if
theproblem was reported already. In this casethere is probably a
fixavailable, similarly check the registeredopenbugs.
- Make sure you can reproduce the bug with xmllint or one of
thetestprograms found in source in the distribution.
- Please send the command showing the error as well as the input
(asanattachment)
Then send the bug with associated information to reproduce it to the xml@gnome.orglist; if it's
reallylibxmlrelated I will approve it. Please do not send mail to me
directly, itmakesthings really hard to track and in some cases I am not the
best persontoanswer a given question, ask on the list.
To be really clear about support:
- Support or help requests MUST be senttothe
list or on bugzillain case of problems, so that theQuestionand
Answers can be shared publicly. Failing to do so carries
theimplicitmessage "I want free support but I don't want to share
thebenefits withothers" and is not welcome. I will automatically
Carbon-Copythexml@gnome.org mailing list for any technical reply made
about libxml2orlibxslt.
- There is no garantee of
support,ifyour question remains unanswered after a week, repost
it, making sureyougave all the detail needed and the information
requested.
- Failing to provide information as requested or double checking
firstforprior feedback also carries the implicit message "the time of
thelibrarymaintainers is less valuable than my time" and might not
bewelcome.
Of course, bugs reported with a suggested patch for fixing
themwillprobably be processed faster than those without.
If you're looking for help, a quick look at the list
archivemayactuallyprovide the answer. I usually send source samples when
answeringlibxml2usage questions. The auto-generateddocumentationisnot
as polished as I would like (i need to learn moreabout DocBook), butit's a
good starting point.
You can help the project in various ways, the best thing to do first
istosubscribe to the mailing-list as explained before, check the archives and the Gnomebugdatabase:
- Provide patches when you find problems.
- Provide the diffs when you port libxml2 to a new platform. They
maynotbe integrated in all cases but help pinpointing
portabilityproblemsand
- Provide documentation fixes (either as patches to the code commentsoras
HTML diffs).
- Provide new documentations pieces (translations, examples, etc...).
- Check the TODO file and try to close one of the items.
- Take one of the points raised in the archive or the bug
databaseandprovide a fix. Get in
touch withmebefore to avoid synchronization problems and check that
thesuggestedfix will fit in nicely :-)
The latest versions of libxml2 can be found on the xmlsoft.orgserver ( HTTP, FTPand rsync are available), there
isalsomirrors (Australia(Web), France) or on the Gnome FTP serveras source
archive,Antonin Sprinzl also provide amirror in Austria. (NOTE
thatyou need both the libxml(2)and libxml(2)-develpackagesinstalled
to compile applications using libxml.)
You can find all the history of libxml(2) and libxslt releases in the olddirectory.
TheprecompiledWindows binaries made by Igor Zlatovic are available in the win32directory.
Binary ports:
If you know other supported binary ports, please contact me.
Snapshot:
Contributions:
I do accept external contributions, especially if compiling
onanotherplatform, get in touch with the list to upload the package,
wrappersforvarious languages have been provided, and can be found in the bindings section
Libxml2 is also available from CVS:
Items not finished and worked on, get in touch with the list if you
wanttohelp those
The change logdescribes the recents
commitstothe CVScode
base.
There is the list of public releases:
2.6.26: Jun 6 2006
- portability fixes: Python detection (Joseph Sacco), compilation
error(William Brack and Graham Bennett), LynxOS patch (Olli Savia)
- bug fixes: encoding buffer problem, mix of code and data in
xmlIO.c(Kjartan Maraas), entities in XSD validation (Kasimier Buchcik),
variousXSD validation fixes (Kasimier), memory leak in pattern (Rob
Richards andKasimier), attribute with colon in name (Rob Richards), XPath
leak inerror reporting (Aleksey Sanin), XInclude text include of
selfdocument.
- improvements: Xpath optimizations (Kasimier), XPath object
cache(Kasimier)
2.6.25: Jun 6 2006:
Do not use or package 2.6.25
2.6.24: Apr 28 2006
- Portability fixes: configure on Windows, testapi compile
onwindows(Kasimier Buchcik, venkat naidu), Borland C++ 6 compile
(EricZurcher),HP-UX compiler workaround (Rick Jones), xml2-config
bugfix,gcc-4.1cleanups, Python detection scheme (Joseph Sacco), UTF-8
file pathsonWindows (Roland Schwingel).
- Improvements: xmlDOMWrapReconcileNamespaces
xmlDOMWrapCloneNode(KasimierBuchcik), XML catalog debugging (Rick Jones),
update to Unicode4.01.
- Bug fixes: xmlParseChunk() problem in 2.6.23,
xmlParseInNodeContext()onHTML docs, URI behaviour on Windows (Rob
Richards), comment streamingbug,xmlParseComment (with William Brack),
regexp bug fixes (DV &YouriGolovanov), xmlGetNodePath on text/CDATA
(Kasimier),one Relax-NGinterleave bug, xmllint --path and --valid,XSD
bugfixes (Kasimier),remove debugleft in Python bindings (Nic Ferrier),
xmlCatalogAdd bug(Martin Cole),xmlSetProp fixes (Rob Richards), HTML
IDness (RobRichards), a largenumber of cleanups and small fixes based on
Coverityreports, bugin character ranges, Unicode tables const (Aivars
Kalvans),schemasfix (Stefan Kost), xmlRelaxNGParse
errordeallocation,xmlSchemaAddSchemaDoc error deallocation, error
handling onunallowedcode point, ixmllint --nonet to never reach the net
(GaryCoady),line break in writer after end PI (Jason Viers).
- Documentation: man pages updates and cleanups (Daniel Leidert).
- New features: Relax NG structure error handlers.
2.6.23: Jan 5 2006
- portability fixes: Windows (Rob Richards), getaddrinfo on
Windows(KoljaNowak, Rob Richards), icc warnings (Kjartan
Maraas),--with-minimumcompilation fixes (William Brack), error case
handling fixon Solaris(Albert Chin), don't use 'list' as parameter name
reported bySamuel DiazGarcia, more old Unices portability fixes (Albert
Chin),MinGW compilation(Mark Junker), HP-UX compiler warnings
(RickJones),
- code cleanup: xmlReportError (Adrian Mouat), removexmlBufferClose(Geert
Jansen), unreachable code (Oleksandr Kononenko),refactoringparsing code
(Bjorn Reese)
- bug fixes: xmlBuildRelativeURI and empty path
(WilliamBrack),combinatory explosion and performances in regexp code,
leakinxmlTextReaderReadString(), xmlStringLenDecodeEntities
problem(MassimoMorara), Identity Constraints bugs and a segfault
(KasimierBuchcik),XPath pattern based evaluation bugs (DV
&Kasimier),xmlSchemaContentModelDump() memory leak (Kasimier),
potentialleak inxmlSchemaCheckCSelectorXPath(), xmlTextWriterVSprintf()
misuseofvsnprintf (William Brack), XHTML serialization fix (Rob
Richards),CRLFsplit problem (William), issues with non-namespaced
attributesinxmlAddChild() xmlAddNextSibling() and xmlAddPrevSibling()
(RobRichards),HTML parsing of script, Python must not output to stdout
(NicFerrier),exclusive C14N namespace visibility (Aleksey Sanin),
XSDdataypetotalDigits bug (Kasimier Buchcik), error handling when writing
toanxmlBuffer (Rob Richards), runtest schemas error not
reported(HisashiFujinaka), signed/unsigned problem in date/time code
(AlbertChin), fixXSI driven XSD validation (Kasimier), parsing of
xs:decimal(Kasimier),fix DTD writer output (Rob Richards), leak
inxmlTextReaderReadInnerXml(Gary Coady), regexp bug affecting
schemas(Kasimier), configuration ofruntime debugging
(Kasimier),xmlNodeBufGetContent bug on entity refs(Oleksandr
Kononenko),xmlRegExecPushString2 bug (Sreeni Nair),compilation and build
fixes(Michael Day), removed dependancies onxmlSchemaValidError
(Kasimier), bugwith <xml:foo/>, more XPathpattern based evaluation
fixes(Kasimier)
- improvements: XSD Schemas redefinitions/restrictions
(KasimierBuchcik),node copy checks and fix for attribute (Rob Richards),
countedtransitionbug in regexps, ctxt->standalone = -2 to indicate
nostandaloneattribute was found, add
xmlSchemaSetParserStructuredErrors()(KasimierBuchcik), add
xmlTextReaderSchemaValidateCtxt() to API(Kasimier), handlegzipped HTTP
resources (Gary Coady), addhtmlDocDumpMemoryFormat. (RobRichards),
- documentation: typo (Michael Day), libxml man page (Albert
Chin),savefunction to XML buffer (Geert Jansen), small doc fix
(AronStansvik),
2.6.22: Sep 12 2005
- build fixes: compile without schematron (St�phane Bidoul)
- bug fixes: xmlDebugDumpNode on namespace node (Oleg
Paraschenko)i,CDATApush parser bug, xmlElemDump problem with XHTML1
doc,XML_FEATURE_xxxclash with expat headers renamed XML_WITH_xxx, fix
someoutput formattingfor meta element (Rob Richards), script and
styleXHTML1 serialization(David Madore), Attribute derivation fixups in
XSD(Kasimier Buchcik),better IDC error reports (Kasimier Buchcik)
- improvements: add XML_SAVE_NO_EMPTY xmlSaveOption (Rob
Richards),addXML_SAVE_NO_XHTML xmlSaveOption, XML Schemas improvements
preparingforderive (Kasimier Buchcik).
- documentation: generation of gtk-doc like docs,
integrationwithdevhelp.
2.6.21: Sep 4 2005
- build fixes: Cygwin portability fixes (Gerrit P.
Haase),callingconvention problems on Windows (Marcus Boerger), cleanups
based onLinus'sparse tool, update of win32/configure.js (Rob Richards),
removewarningson Windows(Marcus Boerger), compilation without SAX1,
detectionof thePython binary, use $GCC inestad of $CC = 'gcc' (Andrew
W.Nosenko),compilation/link with threads and old gcc, compile problem
byC370 onZ/OS,
- bug fixes: http_proxy environments (Peter Breitenlohner), HTML
UTF-8bug(Jiri Netolicky), XPath NaN compare bug (William
Brack),htmlParseScriptpotential bug, Schemas regexp handling of spaces,
Base64Schemascomparisons NIST passes, automata build error
xsd:all,xmlGetNodePath fornamespaced attributes (Alexander Pohoyda),
xmlSchemasforeign namespaceshandling, XML Schemas facet comparison
(KupriyanovAnatolij),xmlSchemaPSimpleTypeErr error report (Kasimier
Buchcik), xml:namespaceahndling in Schemas (Kasimier), empty model group
in Schemas(Kasimier),wilcard in Schemas (Kasimier), URI composition
(William),xs:anyType inSchemas (Kasimier), Python resolver emmitting
errormessages directly,Python xmlAttr.parent (Jakub Piotr Clapa), trying
tofix the file path/URIconversion, xmlTextReaderGetAttribute fix
(RobRichards),xmlSchemaFreeAnnot memleak (Kasimier), HTML
UTF-8serialization, streamingXPath, Schemas determinism detection
problem,XInclude bug, Schemascontext type (Dean Hill), validation fix
(DerekPoon),xmlTextReaderGetAttribute[Ns] namespaces (Rob Richards),
Schemastype fix(Kuba Nowakowski), UTF-8 parser bug, error in
encodinghandling,xmlGetLineNo fixes, bug on entities handling, entity
nameextraction inerror handling with XInclude, text nodes in HTML body
tags(Gary Coady),xml:id and IDness at the treee level fixes, XPath
streamingpatternsbugs.
- improvements: structured interfaces for schemas and RNG
errorreports(Marcus Boerger), optimization of the char data inner
loopparsing(thanks to Behdad Esfahbod for the idea), schematron
validationthoughnot finished yet, xmlSaveOption to omit XML declaration,
keyrefmatcherror reports (Kasimier), formal expression handling code
notpluggedyet, more lax mode for the HTML parser, parser
XML_PARSE_COMPACToptionfor text nodes allocation.
- documentation: xmllint man page had --nonet duplicated
2.6.20: Jul 10 2005
- build fixes: Windows build (Rob Richards), Mingw
compilation(IgorZlatkovic), Windows Makefile (Igor), gcc warnings
(Kasimierandandriy@google.com), use gcc weak references to pthread to
avoidthepthread dependancy on Linux, compilation problem (Steve
Nairn),compilingof subset (Morten Welinder), IPv6/ss_family compilation
(WilliamBrack),compilation when disabling parts of the library,
standalonetestdistribution.
- bug fixes: bug in lang(), memory cleanup on errors (William
Brack),HTTPquery strings (Aron Stansvik), memory leak in DTD
(William),integeroverflow in XPath (William), nanoftp buffer size,
pattern "." apthfixup(Kasimier), leak in tree reported by Malcolm Rowe,
replaceNodepatch(Brent Hendricks), CDATA with NULL content (Mark Vakoc),
xml:basefixupon XInclude (William), pattern fixes (William), attribute
buginexclusive c14n (Aleksey Sanin), xml:space and xml:lang with
SAX2(RobRichards), namespace trouble in complex parsing (Malcolm Rowe),
XSDtypeQNames fixes (Kasimier), XPath streaming fixups (William),
RelaxNGbug(Rob Richards), Schemas for Schemas fixes (Kasimier), removal
of ID(RobRichards), a small RelaxNG leak, HTML parsing in push mode
bug(JamesBursa), failure to detect UTF-8 parsing bugs in
CDATAsections,areBlanks() heuristic failure, duplicate attributes in
DTDbug(William).
- improvements: lot of work on Schemas by Kasimier Buchcik
bothonconformance and streaming, Schemas validation messages
(KasimierBuchcik,Matthew Burgess), namespace removal at the python
level(BrentHendricks), Update to new Schemas regression tests
fromW3C/Nist(Kasimier), xmlSchemaValidateFile() (Kasimier),
implementationofxmlTextReaderReadInnerXml and xmlTextReaderReadOuterXml
(JamesWert),standalone test framework and programs, new DOM
importAPIsxmlDOMWrapReconcileNamespaces()
xmlDOMWrapAdoptNode()andxmlDOMWrapRemoveNode(), extension of xmllint
capabilities for SAXandSchemas regression tests, xmlStopParser()
available in pull modetoo,ienhancement to xmllint --shell namespaces
support, Windows port ofthestandalone testing tools (Kasimier
andWilliam),xmlSchemaValidateStream() xmlSchemaSAXPlug()
andxmlSchemaSAXUnplug() SAXSchemas APIs, Schemas xmlReader support.
2.6.19: Apr 02 2005
- build fixes: drop .la from RPMs, --with-minimum build
fix(WilliamBrack), use XML_SOCKLEN_T instead of SOCKLEN_T because it
breakswith AIX5.3 compiler, fixed elfgcchack.h generation and PLT
reductioncode onLinux/ELF/gcc4
- bug fixes: schemas type decimal fixups (William Brack),
xmmlintreturncode (Gerry Murphy), small schemas fixes (Matthew Burgess
andGUYFabrice), workaround "DAV:" namespace brokeness in c14n
(AlekseySanin),segfault in Schemas (Kasimier Buchcik), Schemas
attributevalidation(Kasimier), Prop related functions and
xmlNewNodeEatName (RobRichards),HTML serialization of name attribute on a
elements, Pythonerror handlersleaks and improvement (Brent Hendricks),
uninitializedvariable inencoding code, Relax-NG validation bug, potential
crashifgnorableWhitespace is NULL, xmlSAXParseDoc and
xmlParseDocsignatures,switched back to assuming UTF-8 in case no encoding
is givenatserialization time
- improvements: lot of work on Schemas by Kasimier Buchcik
onfacetschecking and also mixed handling.
2.6.18: Mar 13 2005
- build fixes: warnings (Peter Breitenlohner),
testapi.cgeneration,Bakefile support (Francesco Montorsi), Windows
compilation(Joel Reed),some gcc4 fixes, HP-UX portability fixes (Rick
Jones).
- bug fixes: xmlSchemaElementDump namespace (Kasimier Buchcik),
pushandxmlreader stopping on non-fatal errors, thread support
fordictionnariesreference counting (Gary Coady), internal subset and
pushproblem, URLsaved in xmlCopyDoc, various schemas bug fixes
(Kasimier),Python pathsfixup (Stephane Bidoul), xmlGetNodePath and
namespaces,xmlSetNsProp fix(Mike Hommey), warning should not count as
error (WilliamBrack),xmlCreatePushParser empty chunk, XInclude parser
flags (William),cleanupFTP and HTTP code to reuse the uri parsing and
IPv6(William),xmlTextWriterStartAttributeNS fix (Rob
Richards),XMLLINT_INDENT beingempty (William), xmlWriter bugs (Rob
Richards),multithreading on Windows(Rich Salz), xmlSearchNsByHref fix
(Kasimier),Python binding leak (BrentHendricks), aliasing bug exposed by
gcc4 ons390, xmlTextReaderNext bug(Rob Richards), Schemas decimal type
fixes(William Brack),xmlByteConsumed static buffer (Ben Maurer).
- improvement: speedup parsing comments and DTDs, dictionnary
supportforhash tables, Schemas Identity constraints (Kasimier),
streamingXPathsubset, xmlTextReaderReadString added (Bjorn Reese),
Schemascanonicalvalues handling (Kasimier), add
xmlTextReaderByteConsumed(AronStansvik),
- Documentation: Wiki support (Joel Reed)
2.6.17: Jan 16 2005
- build fixes: Windows, warnings removal (William
Brack),maintainer-cleandependency(William), build in a different
directory(William), fixing--with-minimum configure build (William), BeOS
build(Marcin Konicki),Python-2.4 detection (William), compilation on AIX
(DanMcNichol)
- bug fixes: xmlTextReaderHasAttributes (Rob
Richards),xmlCtxtReadFile()to use the catalog(s), loop on output (William
Brack),XPath memory leak,ID deallocation problem (Steve Shepard),
debugDumpNodecrash (William),warning not using error callback (William),
xmlStopParserbug (William),UTF-16 with BOM on DTDs (William), namespace
bug on emptyelements inpush mode (Rob Richards), line and col
computations fixups(AlekseySanin), xmlURIEscape fix (William),
xmlXPathErr on bad range(William),patterns with too many steps, bug in
RNG choice optimization,line numbersometimes missing.
- improvements: XSD Schemas (Kasimier Buchcik), pythongenerator(William),
xmlUTF8Strpos speedup (William), unicode Pythonstrings(William), XSD
error reports (Kasimier Buchcik), Python __str__callserialize().
- new APIs: added xmlDictExists(), GetLineNumber and
GetColumnNumberforthe xmlReader (Aleksey Sanin), Dynamic Shared Libraries
APIs (mostlyJoelReed), error extraction API from regexps, new XMLSave
option forformat(Phil Shafer)
- documentation: site improvement (John Fleck), FAQ entries(William).
2.6.16: Nov 10 2004
- general hardening and bug fixing crossing all the API based
onnewautomated regression testing
- build fix: IPv6 build and test on AIX (Dodji Seketeli)
- bug fixes: problem with XML::Libxml reported by Petr
Pajas,encodingconversion functions return values, UTF-8 bug affecting
XPathreported byMarkus Bertheau, catalog problem with NULL entries
(WilliamBrack)
- documentation: fix to xmllint man page, some API
functiondescritpionwere updated.
- improvements: DTD validation APIs provided at the Python
level(BrentHendricks)
2.6.15: Oct 27 2004
- security fixes on the nanoftp and nanohttp modules
- build fixes: xmllint detection bug in configure, building
outsidethesource tree (Thomas Fitzsimmons)
- bug fixes: HTML parser on broken ASCII chars in names
(William),Pythonpaths (Malcolm Tredinnick), xmlHasNsProp and default
namespace(William),saving to python file objects (Malcolm Tredinnick),
DTD lookupfix(Malcolm), save back <group> in catalogs (William),
treebuildfixes (DV and Rob Richards), Schemas memory bug, structured
errorhandleron Python 64bits, thread local memory deallocation, memory
leakreportedby Volker Roth, xmlValidateDtd in the presence of an
internalsubset,entities and _private problem (William),
xmlBuildRelativeURIerror(William).
- improvements: better XInclude error reports (William),
treedebuggingmodule and tests, convenience functions at the Reader
API(GrahamBennett), add support for PI in the HTML parser.
2.6.14: Sep 29 2004
- build fixes: configure paths for xmllint and
xsltproc,compilationwithout HTML parser, compilation warning cleanups
(WilliamBrack &Malcolm Tredinnick), VMS makefile update (Craig
Berry),
- bug fixes: xmlGetUTF8Char (William Brack), QName
properties(KasimierBuchcik), XInclude testing, Notation
serialization,UTF8ToISO8859xtranscoding (Mark Itzcovitz), lots of XML
Schemas cleanupand fixes(Kasimier), ChangeLog cleanup (Stepan Kasal),
memory fixes (MarkVakoc),handling of failed realloc(), out of bound array
adressing inSchemasdate handling, Python space/tabs cleanups (Malcolm
Tredinnick),NMTOKENSE20 validation fix (Malcolm),
- improvements: added W3C XML Schemas testsuite (Kasimier
Buchcik),addxmlSchemaValidateOneElement (Kasimier), Python
exceptionhierearchy(Malcolm Tredinnick), Python libxml2 driver
improvement(MalcolmTredinnick), Schemas support
forxsi:schemaLocation,xsi:noNamespaceSchemaLocation, xsi:type
(KasimierBuchcik)
2.6.13: Aug 31 2004
- build fixes: Windows and zlib (Igor Zlatkovic), -O flag withgcc,Solaris
compiler warning, fixing RPM BuildRequires,
- fixes: DTD loading on Windows (Igor), Schemas error
reportsAPIs(Kasimier Buchcik), Schemas validation crash, xmlCheckUTF8
(WilliamBrackand Julius Mittenzwei), Schemas facet check (Kasimier),
defaultnamespaceproblem (William), Schemas hexbinary empty values,
encodingerror couldgenrate a serialization loop.
- Improvements: Schemas validity improvements (Kasimier), added
--pathand--load-trace options to xmllint
- documentation: tutorial update (John Fleck)
2.6.12: Aug 22 2004
- build fixes: fix --with-minimum, elfgcchack.h
fixes(PeterBreitenlohner), perl path lookup (William), diff on
Solaris(AlbertChin), some 64bits cleanups.
- Python: avoid a warning with 2.3 (William Brack), tab and
spacemixes(William), wrapper generator fixes (William), Cygwin support
(GerritP.Haase), node wrapper fix (Marc-Antoine Parent), XML
Schemassupport(Torkel Lyng)
- Schemas: a lot of bug fixes and improvements from Kasimier Buchcik
- fixes: RVT fixes (William), XPath context resets bug
(William),memorydebug (Steve Hay), catalog white space handling
(PeterBreitenlohner),xmlReader state after attribute reading
(William),structured errorhandler (William), XInclude generated xml:base
fixup(William), Windowsmemory reallocation problem (Steve Hay), Out of
Memoryconditionshandling (William and Olivier Andrieu), htmlNewDoc()
charsetbug,htmlReadMemory init (William), a posteriori validation
DTDbase(William), notations serialization missing,
xmlGetNodePath(Dodji),xmlCheckUTF8 (Diego Tartara), missing line numbers
onentity(William)
- improvements: DocBook catalog build scrip (William),
xmlcatalogtool(Albert Chin), xmllint --c14n option, no_proxy environment
(MikeHommey),xmlParseInNodeContext() addition, extend xmllint --shell,
allowXIncludeto not generate start/end nodes, extend xmllint --version
toinclude CVStag (William)
- documentation: web pages fixes, validity API docs fixes(William)schemas
API fix (Eric Haszlakiewicz), xmllint man page (JohnFleck)
2.6.11: July 5 2004
- Schemas: a lot of changes and improvements by Kasimier
Buchcikforattributes, namespaces and simple types.
- build fixes: --with-minimum (William Brack), some gcccleanup(William),
--with-thread-alloc (William)
- portability: Windows binary package change (Igor Zlatkovic),Catalogpath
on Windows
- documentation: update to the tutorial (John Fleck), xmllint
returncode(John Fleck), man pages (Ville Skytta),
- bug fixes: C14N bug serializing namespaces (Aleksey
Sanin),testSAXproperly initialize the library (William), empty node set
inXPath(William), xmlSchemas errors (William), invalid charref
problempointedby Morus Walter, XInclude xml:base generation (William),
Relax-NGbugwith div processing (William), XPointer and
xml:baseproblem(William),Reader and entities, xmllint return code for
schemas(William), readerstreaming problem (Steve Ball), DTD
serializationproblem (William),libxml.m4 fixes (Mike Hommey), do not
providedestructors as methods onPython classes, xmlReader buffer bug,
Pythonbindings memory interfacesimprovement (with St�phane Bidoul), Fixed
thepush parser to be back tosynchronous behaviour.
- improvement: custom per-thread I/O enhancement (Rob
Richards),registernamespace in debug shell (Stefano Debenedetti), Python
basedregressiontest for non-Unix users (William), dynamically increase
thenumber ofXPath extension functions in Python and fix a memory
leak(Marc-AntoineParent and William)
- performance: hack done with Arjan van de Ven to reduce ELF
footprintandgenerated code on Linux, plus use gcc runtime profiling to
optimizethecode generated in the RPM packages.
2.6.10: May 17 2004
- Web page generated for ChangeLog
- build fixes: --without-html problems, make check without make all
- portability: problem with xpath.c on Windows (MSC and
Borland),memcmpvs. strncmp on Solaris, XPath tests on Windows (Mark
Vakoc), C++ donotuse "list" as parameter name, make tests work with
Python 1.5(EdDavis),
- improvements: made xmlTextReaderMode public, small
buffersresizing(Morten Welinder), add --maxmem option to
xmllint,addxmlPopInputCallback() for Matt Sergeant, refactoring
ofserializationescaping, added escaping customization
- bugfixes: xsd:extension (Taihei Goi), assorted regexp
bugs(WilliamBrack), xmlReader end of stream problem, node deregistration
withreader,URI escaping and filemanes, XHTML1 formatting (Nick
Wellnhofer),regexptransition reduction (William), various XSD Schemas
fixes(KasimierBuchcik), XInclude fallback problem (William), weird
problemswith DTD(William), structured error handler callback context
(William),reversexmlEncodeSpecialChars() behaviour back to escaping
'"'
2.6.9: Apr 18 2004
- implement xml:id Working Draft, relaxed XPath id() checking
- bugfixes: xmlCtxtReset (Brent Hendricks), line number and
CDATA(DaveBeckett), Relax-NG compilation (William Brack), Regexp
patches(withWilliam), xmlUriEscape (Mark Vakoc), a Relax-NG notAllowed
problem(withWilliam), Relax-NG name classes compares (William),
XIncludeduplicatefallback (William), external DTD encoding detection
(William), aDTDvalidation bug (William), xmlReader Close() fix,
recusiveextentionschemas
- improvements: use xmlRead* APIs in test tools (Mark
Vakoc),indentingsave optimization, better handle IIS broken HTTP
redirectbehaviour (IanHummel), HTML parser frameset (James Bursa),
libxml2-pythonRPMdependancy, XML Schemas union support (Kasimier
Buchcik), warningremovalclanup (William), keep ChangeLog compressed when
installing fromRPMs
- documentation: examples and xmlDocDumpMemory docs (John
Fleck),newexample (load, xpath, modify, save), xmlCatalogDump()
comments,
- Windows: Borland C++ builder (Eric Zurcher), work
aroundMicrosoftcompiler NaN handling bug (Mark Vakoc)
2.6.8: Mar 23 2004
- First step of the cleanup of the serialization code and APIs
- XML Schemas: mixed content (Adam Dickmeiss), QName handling
fixes(AdamDickmeiss), anyURI for "" (John Belmonte)
- Python: Canonicalization C14N support added (Anthony Carrico)
- xmlDocCopyNode() extension (William)
- Relax-NG: fix when processing XInclude results
(William),externalreference in interleave (William), missing error
on<choice>failure (William), memory leak in schemas
datatypefacets.
- xmlWriter: patch for better DTD support (Alfred Mickautsch)
- bug fixes: xmlXPathLangFunction memory leak (Mike Hommey
andWilliamBrack), no ID errors if using HTML_PARSE_NOERROR,
xmlcatalogfallbacks toURI on SYSTEM lookup failure, XInclude parse
flagsinheritance (William),XInclude and XPointer fixes for entities
(William),XML parser bugreported by Holger Rauch, nanohttp fd leak
(William),regexps chargroups '-' handling (William), dictionnary
reference countingproblems,do not close stderr.
- performance patches from Petr Pajas
- Documentation fixes: XML_CATALOG_FILES in man pages (Mike Hommey)
- compilation and portability fixes: --without-valid,
catalogcleanups(Peter Breitenlohner), MingW patch (Roland
Schwingel),cross-compilationto Windows (Christophe de Vienne),
--with-html-dirfixup (Julio MerinoVidal), Windows build (Eric
Zurcher)
2.6.7: Feb 23 2004
- documentation: tutorial updates (John Fleck), benchmark results
- xmlWriter: updates and fixes (Alfred Mickautsch, Lucas Brasilino)
- XPath optimization (Petr Pajas)
- DTD ID handling optimization
- bugfixes: xpath number with > 19 fractional (William
Brack),pushmode with unescaped '>' characters, fix xmllint --stream
--timing,fixxmllint --memory --stream memory
usage,xmlAttrSerializeTxtContenthandling NULL, trying to fix
Relax-NG/Perlinterface.
- python: 2.3 compatibility, whitespace fixes (Malcolm Tredinnick)
- Added relaxng option to xmllint --shell
2.6.6: Feb 12 2004
- nanohttp and nanoftp: buffer overflow error on URI parsing
(IgorandWilliam) reported by Yuuichi Teranishi
- bugfixes: make test and path issues, xmlWriter
attributeserialization(William Brack), xmlWriter indentation (William),
schemasvalidation(Eric Haszlakiewicz), XInclude dictionnaries issues
(Williamand OlegParaschenko), XInclude empty fallback (William), HTML
warnings(William),XPointer in XInclude (William), Python
namespaceserialization,isolat1ToUTF8 bound error (Alfred Mickautsch),
output ofparameterentities in internal subset (William), internal subset
bug inpush mode,<xs:all> fix (Alexey Sarytchev)
- Build: fix for automake-1.8 (Alexander Winston), warningsremoval(Philip
Ludlam), SOCKLEN_T detection fixes (Daniel Richard),fix--with-minimum
configuration.
- XInclude: allow the 2001 namespace without warning.
- Documentation: missing example/index.html (John
Fleck),versiondependancies (John Fleck)
- reader API: structured error reporting (Steve Ball)
- Windows compilation: mingw, msys (Mikhail
Grushinskiy),functionprototype (Cameron Johnson), MSVC6 compiler
warnings,_WINSOCKAPI_patch
- Parsers: added xmlByteConsumed(ctxt) API to get the byte
offestininput.
2.6.5: Jan 25 2004
- Bugfixes: dictionnaries for schemas (William Brack),
regexpsegfault(William), xs:all problem (William), a number of
XPointerbugfixes(William), xmllint error go to stderr, DTD validation
problemwithnamespace, memory leak (William), SAX1 cleanup and minimal
optionsfixes(Mark Vadoc), parser context reset on error (Shaun McCance),
XPathunionevaluation problem (William) , xmlReallocLoc with NULL
(AlekseySanin),XML Schemas double free (Steve Ball), XInclude with no
href,argumentcallbacks order for XPath callbacks (Frederic Peters)
- Documentation: python scripts (William Brack), xslt
stylesheets(JohnFleck), doc (Sven Zimmerman), I/O example.
- Python bindings: fixes (William), enum support
(St�phaneBidoul),structured error reporting (St�phane Bidoul)
- XInclude: various fixes for conformance, problem related
todictionnaryreferences (William & me), recursion (William)
- xmlWriter: indentation (Lucas Brasilino), memory
leaks(AlfredMickautsch),
- xmlSchemas: normalizedString datatype (John Belmonte)
- code cleanup for strings functions (William)
- Windows: compiler patches (Mark Vakoc)
- Parser optimizations, a few new XPath and dictionnary APIs
forfutureXSLT optimizations.
2.6.4: Dec 24 2003
- Windows build fixes (Igor Zlatkovic)
- Some serious XInclude problems reported by Oleg Paraschenko and
- Unix and Makefile packaging fixes (me, William Brack,
- Documentation improvements (John Fleck, William Brack),
examplefix(Lucas Brasilino)
- bugfixes: xmlTextReaderExpand() with xmlReaderWalker, XPath
handlingofNULL strings (William Brack) , API building reader or
parserfromfiledescriptor should not close it, changed XPath sorting to
bestableagain (William Brack), xmlGetNodePath() generating
'(null)'(WilliamBrack), DTD validation and namespace bug (William Brack),
XMLSchemasdouble inclusion behaviour
2.6.3: Dec 10 2003
- documentation updates and cleanup (DV, William Brack, John Fleck)
- added a repository of examples, examples from Aleksey
Sanin,DodjiSeketeli, Alfred Mickautsch
- Windows updates: Mark Vakoc, Igor Zlatkovic, Eric Zurcher,Mingw(Kenneth
Haley)
- Unicode range checking (William Brack)
- code cleanup (William Brack)
- Python bindings: doc (John Fleck), bug fixes
- UTF-16 cleanup and BOM issues (William Brack)
- bug fixes: ID and xmlReader validation, XPath (William
Brack),xmlWriter(Alfred Mickautsch), hash.h inclusion problem, HTML
parser(James Bursa),attribute defaulting and validation, some
serializationcleanups,XML_GET_LINE macro, memory debug when using threads
(WilliamBrack),serialization of attributes and entities content,
xmlWriter(DanielSchulman)
- XInclude bugfix, new APIs and update to the last version
includingthenamespace change.
- XML Schemas improvements: include (Robert Stepanek), importandnamespace
handling, fixed the regression tests troubles, addedexamplesbased on Eric
van der Vlist book, regexp fixes
- preliminary pattern support for streaming (needed
forschemasconstraints), added xmlTextReaderPreservePattern() to
collectsubdocumentwhen streaming.
- various fixes in the structured error handling
2.6.2: Nov 4 2003
- XPath context unregistration fixes
- text node coalescing fixes (Mark Lilback)
- API to screate a W3C Schemas from an existing document (Steve Ball)
- BeOS patches (Marcin 'Shard' Konicki)
- xmlStrVPrintf function added (Aleksey Sanin)
- compilation fixes (Mark Vakoc)
- stdin parsing fix (William Brack)
- a posteriori DTD validation fixes
- xmlReader bug fixes: Walker fixes, python bindings
- fixed xmlStopParser() to really stop the parser and errors
- always generate line numbers when using the new xmlReadxxxfunctions
- added XInclude support to the xmlReader interface
- implemented XML_PARSE_NONET parser option
- DocBook XSLT processing bug fixed
- HTML serialization for <p> elements (William Brack and me)
- XPointer failure in XInclude are now handled as resource errors
- fixed xmllint --html to use the HTML serializer on output(added--xmlout
to implement the previous behaviour of saving it using
theXMLserializer)
2.6.1: Oct 28 2003
- Mostly bugfixes after the big 2.6.0 changes
- Unix compilation patches: libxml.m4 (Patrick Welche),
warningscleanup(William Brack)
- Windows compilation patches (Joachim Bauch, Stephane
Bidoul,IgorZlatkovic)
- xmlWriter bugfix (Alfred Mickautsch)
- chvalid.[ch]: couple of fixes from Stephane Bidoul
- context reset: error state reset, push parser reset (GrahamBennett)
- context reuse: generate errors if file is not readable
- defaulted attributes for element coming from internal
entities(StephaneBidoul)
- Python: tab and spaces mix (William Brack)
- Error handler could crash in DTD validation in 2.6.0
- xmlReader: do not use the document or element _private field
- testSAX.c: avoid a problem with some PIs (Massimo Morara)
- general bug fixes: mandatory encoding in text decl,
serializingDocumentFragment nodes, xmlSearchNs 2.6.0 problem (Kasimier
Buchcik),XPath errorsnot reported, slow HTML parsing of large
documents.
2.6.0: Oct 20 2003
- Major revision release: should be API and ABI compatible but got alotof
change
- Increased the library modularity, far more options can be strippedout,a
--with-minimum configuration will weight around 160KBytes
- Use per parser and per document dictionnary, allocate names
andsmalltext nodes from the dictionnary
- Switch to a SAX2 like parser rewrote most of the XML
parsercore,provides namespace resolution and defaulted attributes,
minimizememoryallocations and copies, namespace checking and specific
errorhandling,immutable buffers, make predefined entities static
structures,etc...
- rewrote all the error handling in the library, all errors
canbeintercepted at a structured level, with
preciseinformationavailable.
- New simpler and more generic XML and HTML parser APIs,
allowingtoeasilly modify the parsing options and reuse parser context
formultipleconsecutive documents.
- Similar new APIs for the xmlReader, for options and reuse,
providednewfunctions to access content as const strings, use them
forPythonbindings
- a lot of other smaller API improvements: xmlStrPrintf
(AlekseySanin),Walker i.e. reader on a document tree based on Alfred
Mickautschcode,make room in nodes for line numbers, reference counting
and futurePSVIextensions, generation of character ranges to be checked
withfasteralgorithm (William), xmlParserMaxDepth (Crutcher
Dunnavant),bufferaccess
- New xmlWriter API provided by Alfred Mickautsch
- Schemas: base64 support by Anthony Carrico
- Parser<->HTTP integration fix, proper processing of
theMime-Typeand charset informations if available.
- Relax-NG: bug fixes including the one reported by Martijn
FaassenandzeroOrMore, better error reporting.
- Python bindings (St�phane Bidoul), never use stdout forerrorsoutput
- Portability: all the headers have macros for export
andcallingconvention definitions (Igor Zlatkovic), VMS update (Craig
A.Berry),Windows: threads (Jesse Pelton), Borland compiler (Eric
Zurcher,Igor),Mingw (Igor), typos (Mark Vakoc), beta version
(StephaneBidoul),warning cleanups on AIX and MIPS compilers (William
Brack), BeOS(Marcin'Shard' Konicki)
- Documentation fixes and README (William Brack), search
fix(William),tutorial updates (John Fleck), namespace docs (Stefan
Kost)
- Bug fixes: xmlCleanupParser (Dave Beckett),
threadinguninitializedmutexes, HTML doctype lowercase, SAX/IO
(William),compression detectionand restore (William), attribute
declaration in DTDs(William), namespaceon attribute in HTML output
(William), input filename(Rob Richards),namespace DTD validation,
xmlReplaceNode (Chris Ryland),I/O callbacks(Markus Keim), CDATA
serialization (Shaun McCance),xmlReader (PeterDerr), high codepoint
charref like , bufferaccess in pushmode (Justin Fletcher),
TLS threads on Windows (JessePelton), XPath bug(William),
xmlCleanupParser (Marc Liyanage), CDATAoutput (William), HTTPerror
handling.
- xmllint options: --dtdvalidfpi for Tobias Reif, --sax1
forcompattesting, --nodict for building without tree dictionnary,
--nocdatatoreplace CDATA by text, --nsclean to remove
surperfluousnamespacedeclarations
- added xml2-config --libtool-libs option from Kevin P. Fleming
- a lot of profiling and tuning of the code, speedup
patchforxmlSearchNs() by Luca Padovani. The xmlReader should do
farlessallocation and it speed should get closer to SAX. Chris
Andersonworkedon speeding and cleaning up repetitive checking code.
- cleanup of "make tests"
- libxml-2.0-uninstalled.pc from Malcolm Tredinnick
- deactivated the broken docBook SGML parser code and plugged
theXMLparser instead.
2.5.11: Sep 9 2003
A bugfix only release:
- risk of crash in Relax-NG
- risk of crash when using multithreaded programs
2.5.10: Aug 15 2003
A bugfixes only release
- Windows Makefiles (William Brack)
- UTF-16 support fixes (Mark Itzcovitz)
- Makefile and portability (William Brack) automake, Linux alpha,
MingwonWindows (Mikhail Grushinskiy)
- HTML parser (Oliver Stoeneberg)
- XInclude performance problem reported by Kevin Ruscoe
- XML parser performance problem reported by Grant Goodale
- xmlSAXParseDTD() bug fix from Malcolm Tredinnick
- and a couple other cleanup
2.5.9: Aug 9 2003
- bugfixes: IPv6 portability, xmlHasNsProp (Markus Keim),
Windowsbuild(Wiliam Brake, Jesse Pelton, Igor), Schemas (Peter
Sobisch),threading(Rob Richards), hexBinary type (), UTF-16 BOM
(DodjiSeketeli),xmlReader, Relax-NG schemas compilation, namespace
handling,EXSLT (SeanGriffin), HTML parsing problem (William Brack), DTD
validationfor mixedcontent + namespaces, HTML serialization,
libraryinitialization,progressive HTML parser
- better interfaces for Relax-NG error handling (Joachim Bauch, )
- adding xmlXIncludeProcessTree() for XInclud'ing in a subtree
- doc fixes and improvements (John Fleck)
- configure flag for -with-fexceptions when embedding in C++
- couple of new UTF-8 helper functions (William Brack)
- general encoding cleanup + ISO-8859-x without iconv (Peter Jacobi)
- xmlTextReader cleanup + enum for node types (Bjorn Reese)
- general compilation/warning cleanup Solaris/HP-UX/...(WilliamBrack)
2.5.8: Jul 6 2003
- bugfixes: XPath, XInclude, file/URI mapping, UTF-16
save(MarkItzcovitz), UTF-8 checking, URI saving, error printing
(WilliamBrack),PI related memleak, compilation without schemas or without
xpath(JoergSchmitz-Linneweber/Garry Pennington), xmlUnlinkNode problem
withDTDs,rpm problem on , i86_64, removed a few compilation problems
from2.5.7,xmlIOParseDTD, and xmlSAXParseDTD (Malcolm Tredinnick)
- portability: DJGPP (MsDos) , OpenVMS (Craig A. Berry)
- William Brack fixed multithreading lock problems
- IPv6 patch for FTP and HTTP accesses (Archana Shah/Wipro)
- Windows fixes (Igor Zlatkovic, Eric Zurcher),
threading(St�phaneBidoul)
- A few W3C Schemas Structure improvements
- W3C Schemas Datatype improvements (Charlie Bozeman)
- Python bindings for thread globals (St�phane Bidoul),
andmethod/classgenerator
- added --nonet option to xmllint
- documentation improvements (John Fleck)
2.5.7: Apr 25 2003
- Relax-NG: Compiling to regexp and streaming validation on top
ofthexmlReader interface, added to xmllint --stream
- xmlReader: Expand(), Next() and DOM access glue, bug fixes
- Support for large files: RGN validated a 4.5GB instance
- Thread support is now configured in by default
- Fixes: update of the Trio code (Bjorn), WXS Date and
Durationfixes(Charles Bozeman), DTD and namespaces (Brent Hendricks),
HTML pushparserand zero bytes handling, some missing Windows file
pathconversions,behaviour of the parser and validator in the presence of
"outof memory"error conditions
- extended the API to be able to plug a garbage
collectingmemoryallocator, added xmlMallocAtomic() and modified
theallocationsaccordingly.
- Performances: removed excessive malloc() calls, speedup of the
pushandxmlReader interfaces, removed excessive thread locking
- Documentation: man page (John Fleck), xmlReader documentation
- Python: adding binding for xmlCatalogAddLocal (Brent M Hendricks)
2.5.6: Apr 1 2003
- Fixed W3C XML Schemas datatype, should be compliant now exceptforbinHex
and base64 which are not supported yet.
- bug fixes: non-ASCII IDs, HTML output, XInclude on large
docsandXInclude entities handling, encoding detection on external
subsets,XMLSchemas bugs and memory leaks, HTML parser (James Bursa)
- portability: python/trio (Albert Chin), Sun compiler warnings
- documentation: added --relaxng option to xmllint man page (John)
- improved error reporting: xml:space, start/end tag mismatches,
RelaxNGerrors
2.5.5: Mar 24 2003
- Lot of fixes on the Relax NG implementation. More
testingincludingDocBook and TEI examples.
- Increased the support for W3C XML Schemas datatype
- Several bug fixes in the URI handling layer
- Bug fixes: HTML parser, xmlReader, DTD validation,
XPath,encodingconversion, line counting in the parser.
- Added support for $XMLLINT_INDENT environment variable, FTP delete
- Fixed the RPM spec file name
2.5.4: Feb 20 2003
2.5.3: Feb 10 2003
- RelaxNG and XML Schemas datatypes improvements, and added afirstversion
of RelaxNG Python bindings
- Fixes: XLink (Sean Chittenden), XInclude (Sean Chittenden), API
fixforserializing namespace nodes, encoding conversion
bug,XHTML1serialization
- Portability fixes: Windows (Igor), AMD 64bits RPM spec file
2.5.2: Feb 5 2003
- First implementation of RelaxNG, added --relaxng flag to xmllint
- Schemas support now compiled in by default.
- Bug fixes: DTD validation, namespace checking, XInclude
andentities,delegateURI in XML Catalogs, HTML parser, XML reader
(St�phaneBidoul),XPath parser and evaluation, UTF8ToUTF8 serialization,
XMLreader memoryconsumption, HTML parser, HTML serialization in the
presenceofnamespaces
- added an HTML API to check elements and attributes.
- Documentation improvement, PDF for the tutorial (John Fleck),docpatches
(Stefan Kost)
- Portability fixes: NetBSD (Julio Merino), Windows (Igor Zlatkovic)
- Added python bindings for XPointer, contextual error
reporting(St�phaneBidoul)
- URI/file escaping problems (Stefano Zacchiroli)
2.5.1: Jan 8 2003
- Fixes a memory leak and configuration/compilation problems in 2.5.0
- documentation updates (John)
- a couple of XmlTextReader fixes
2.5.0: Jan 6 2003
- New XmltextReader interfacebased on
C#API(with help of St�phane Bidoul)
- Windows: more exports, including the new API (Igor)
- XInclude fallback fix
- Python: bindings for the new API, packaging
(St�phaneBidoul),drv_libxml2.py Python xml.sax driver (St�phane Bidoul),
fixes,speedupand iterators for Python-2.2 (Hannu Krosing)
- Tutorial fixes (john Fleck and Niraj Tolia) xmllint manupdate(John)
- Fix an XML parser bug raised by Vyacheslav Pindyura
- Fix for VMS serialization (Nigel Hall) and config (Craig A. Berry)
- Entities handling fixes
- new API to optionally track node creation and
deletion(LukasSchroeder)
- Added documentation for the XmltextReader interface and some XML guidelines
2.4.30: Dec 12 2002
- 2.4.29 broke the python bindings, rereleasing
- Improvement/fixes of the XML API generator, and couple of
minorcodefixes.
2.4.29: Dec 11 2002
- Windows fixes (Igor): Windows CE port, pthread linking,
pythonbindings(St�phane Bidoul), Mingw (Magnus Henoch), and export
listupdates
- Fix for prev in python bindings (ERDI Gergo)
- Fix for entities handling (Marcus Clarke)
- Refactored the XML and HTML dumps to a single code path,
fixedXHTML1dump
- Fix for URI parsing when handling URNs with fragment identifiers
- Fix for HTTP URL escaping problem
- added an TextXmlReader (C#) like API (work in progress)
- Rewrote the API in XML generation script, includes a C parser
andsavesmore informations needed for C# bindings
2.4.28: Nov 22 2002
- a couple of python binding fixes
- 2 bug fixes in the XML push parser
- potential memory leak removed (Martin Stoilov)
- fix to the configure script for Unix (Dimitri Papadopoulos)
- added encoding support for XInclude parse="text"
- autodetection of XHTML1 and specific serialization rules added
- nasty threading bug fixed (William Brack)
2.4.27: Nov 17 2002
- fixes for the Python bindings
- a number of bug fixes: SGML catalogs,xmlParseBalancedChunkMemory(),HTML
parser, Schemas (Charles Bozeman),document fragment support(Christian
Glahn), xmlReconciliateNs (BrianStafford), XPointer,xmlFreeNode(),
xmlSAXParseMemory (Peter Jones),xmlGetNodePath (PetrPajas), entities
processing
- added grep to xmllint --shell
- VMS update patch from Craig A. Berry
- cleanup of the Windows build with support for more
compilers(Igor),better thread support on Windows
- cleanup of Unix Makefiles and spec file
- Improvements to the documentation (John Fleck)
2.4.26: Oct 18 2002
- Patches for Windows CE port, improvements on Windows paths handling
- Fixes to the validation code (DTD and Schemas), xmlNodeGetPath()
,HTMLserialization, Namespace compliance, and a number of
smallproblems
2.4.25: Sep 26 2002
- A number of bug fixes: XPath, validation, Python bindings, DOM
andtree,xmlI/O, Html
- Serious rewrite of XInclude
- Made XML Schemas regexp part of the default build and APIs, smallfixand
improvement of the regexp core
- Changed the validation code to reuse XML Schemas regexp APIs
- Better handling of Windows file paths, improvement of
Makefiles(Igor,Daniel Gehriger, Mark Vakoc)
- Improved the python I/O bindings, the tests, added resolver
andregexpAPIs
- New logos from Marc Liyanage
- Tutorial improvements: John Fleck, Christopher Harris
- Makefile: Fixes for AMD x86_64 (Mandrake),
DESTDIR(ChristopheMerlet)
- removal of all stderr/perror use for error reporting
- Better error reporting: XPath and DTD validation
- update of the trio portability layer (Bjorn Reese)
2.4.24: Aug 22 2002
- XPath fixes (William), xf:escape-uri() (Wesley Terpstra)
- Python binding fixes: makefiles (William), generator, rpm
build,x86-64(fcrozat)
- HTML <style> and boolean attributes serializer fixes
- C14N improvements by Aleksey
- doc cleanups: Rick Jones
- Windows compiler makefile updates: Igor and Elizabeth Barham
- XInclude: implementation of fallback and xml:base fixup added
2.4.23: July 6 2002
- performances patches: Peter Jacobi
- c14n fixes, testsuite and performances: Aleksey Sanin
- added xmlDocFormatDump: Chema Celorio
- new tutorial: John Fleck
- new hash functions and performances: Sander Vesik, portability
fixfromPeter Jacobi
- a number of bug fixes: XPath (William Brack, Richard Jinks), XMLandHTML
parsers, ID lookup function
- removal of all remaining sprintf: Aleksey Sanin
2.4.22: May 27 2002
- a number of bug fixes: configure scripts, base handling,
parser,memoryusage, HTML parser, XPath, documentation
(ChristianCornelssen),indentation, URI parsing
- Optimizations for XMLSec, fixing and making public some of
thenetworkprotocol handlers (Aleksey)
- performance patch from Gary Pennington
- Charles Bozeman provided date and time support for
XMLSchemasdatatypes
2.4.21: Apr 29 2002
This release is both a bug fix release and also contains the
earlyXMLSchemas structuresand
datatypescode,
beware,allinterfaces are likely to change, there is huge holes, it is clearly
a workinprogress and don't even think of putting this code in a
productionsystem,it's actually not compiled in by default. The real fixes
are:
- a couple of bugs or limitations introduced in 2.4.20
- patches for Borland C++ and MSC by Igor
- some fixes on XPath strings and conformance patches by RichardJinks
- patch from Aleksey for the ExcC14N specification
- OSF/1 bug fix by Bjorn
2.4.20: Apr 15 2002
- bug fixes: file descriptor leak, XPath, HTML output, DTD validation
- XPath conformance testing by Richard Jinks
- Portability fixes: Solaris, MPE/iX, Windows, OSF/1,
pythonbindings,libxml.m4
2.4.19: Mar 25 2002
- bug fixes: half a dozen XPath bugs, Validation, ISO-Latin
toUTF8encoder
- portability fixes in the HTTP code
- memory allocation checks using valgrind, and profiling tests
- revamp of the Windows build and Makefiles
2.4.18: Mar 18 2002
- bug fixes: tree, SAX, canonicalization,
validation,portability,XPath
- removed the --with-buffer option it was becoming unmaintainable
- serious cleanup of the Python makefiles
- speedup patch to XPath very effective for DocBook stylesheets
- Fixes for Windows build, cleanup of the documentation
2.4.17: Mar 8 2002
- a lot of bug fixes, including "namespace nodes have no
parentsinXPath"
- fixed/improved the Python wrappers, added more examples
andmoreregression tests, XPath extension functions can now
returnnode-sets
- added the XML Canonicalization support from Aleksey Sanin
2.4.16: Feb 20 2002
- a lot of bug fixes, most of them were triggered by the XMLTestsuitefrom
OASIS and W3C. Compliance has been significantlyimproved.
- a couple of portability fixes too.
2.4.15: Feb 11 2002
- Fixed the Makefiles, especially the python module ones
- A few bug fixes and cleanup
- Includes cleanup
2.4.14: Feb 8 2002
- Change of License to the MITLicensebasicallyfor
integration in XFree86 codebase, and removingconfusion around theprevious
dual-licensing
- added Python bindings, beta software but should already
bequitecomplete
- a large number of fixes and cleanups, especially for
alltreemanipulations
- cleanup of the headers, generation of a reference API
definitioninXML
2.4.13: Jan 14 2002
- update of the documentation: John Fleck and Charlie Bozeman
- cleanup of timing code from Justin Fletcher
- fixes for Windows and initial thread support on Win32: Igor
andSergueiNarojnyi
- Cygwin patch from Robert Collins
- added xmlSetEntityReferenceFunc() for Keith Isdale work on xsldbg
2.4.12: Dec 7 2001
- a few bug fixes: thread (Gary Pennington), xmllint
(GeertKloosterman),XML parser (Robin Berjon), XPointer (Danny Jamshy),
I/Ocleanups(robert)
- Eric Lavigne contributed project files for MacOS
- some makefiles cleanups
2.4.11: Nov 26 2001
- fixed a couple of errors in the includes, fixed a few bugs,
somecodecleanups
- xmllint man pages improvement by Heiko Rupp
- updated VMS build instructions from John A Fotheringham
- Windows Makefiles updates from Igor
2.4.10: Nov 10 2001
- URI escaping fix (Joel Young)
- added xmlGetNodePath() (for paths or XPointers generation)
- Fixes namespace handling problems when using DTD and validation
- improvements on xmllint: Morus Walter patches for --format
and--encode,Stefan Kost and Heiko Rupp improvements on the --shell
- fixes for xmlcatalog linking pointed by Weiqi Gao
- fixes to the HTML parser
2.4.9: Nov 6 2001
- fixes more catalog bugs
- avoid a compilation problem, improve xmlGetLineNo()
2.4.8: Nov 4 2001
- fixed SGML catalogs broken in previous release,
updatedxmlcatalogtool
- fixed a compile errors and some includes troubles.
2.4.7: Oct 30 2001
- exported some debugging interfaces
- serious rewrite of the catalog code
- integrated Gary Pennington thread safety patch, added
configureoptionand regression tests
- removed an HTML parser bug
- fixed a couple of potentially serious validation bugs
- integrated the SGML DocBook support in xmllint
- changed the nanoftp anonymous login passwd
- some I/O cleanup and a couple of interfaces for Perl wrapper
- general bug fixes
- updated xmllint man page by John Fleck
- some VMS and Windows updates
2.4.6: Oct 10 2001
- added an updated man pages by John Fleck
- portability and configure fixes
- an infinite loop on the HTML parser was removed (William)
- Windows makefile patches from Igor
- fixed half a dozen bugs reported for libxml or libxslt
- updated xmlcatalog to be able to modify SGML super catalogs
2.4.5: Sep 14 2001
- Remove a few annoying bugs in 2.4.4
- forces the HTML serializer to output decimal charrefs since
someversionof Netscape can't handle hexadecimal ones
1.8.16: Sep 14 2001
- maintenance release of the old libxml1 branch, couple of
bugandportability fixes
2.4.4: Sep 12 2001
- added --convert to xmlcatalog, bug fixes and cleanups of XMLCatalog
- a few bug fixes and some portability changes
- some documentation cleanups
2.4.3: Aug 23 2001
- XML Catalog support see the doc
- New NaN/Infinity floating point code
- A few bug fixes
2.4.2: Aug 15 2001
- adds xmlLineNumbersDefault() to control line number generation
- lot of bug fixes
- the Microsoft MSC projects files should now be up to date
- inheritance of namespaces from DTD defaulted attributes
- fixes a serious potential security bug
- added a --format option to xmllint
2.4.1: July 24 2001
- possibility to keep line numbers in the tree
- some computation NaN fixes
- extension of the XPath API
- cleanup for alpha and ia64 targets
- patch to allow saving through HTTP PUT or POST
2.4.0: July 10 2001
- Fixed a few bugs in XPath, validation, and tree handling.
- Fixed XML Base implementation, added a couple of examples
totheregression tests
- A bit of cleanup
2.3.14: July 5 2001
- fixed some entities problems and reduce memory
requirementwhensubstituting them
- lots of improvements in the XPath queries interpreter
canbesubstantially faster
- Makefiles and configure cleanups
- Fixes to XPath variable eval, and compare on empty node set
- HTML tag closing bug fixed
- Fixed an URI reference computation problem when validating
2.3.13: June 28 2001
- 2.3.12 configure.in was broken as well as the push mode XML parser
- a few more fixes for compilation on Windows MSC by Yon Derek
1.8.14: June 28 2001
- Zbigniew Chyla gave a patch to use the old XML parser in push mode
- Small Makefile fix
2.3.12: June 26 2001
- lots of cleanup
- a couple of validation fix
- fixed line number counting
- fixed serious problems in the XInclude processing
- added support for UTF8 BOM at beginning of entities
- fixed a strange gcc optimizer bugs in xpath handling of
float,gcc-3.0miscompile uri.c (William), Thomas Leitner provided a fix
fortheoptimizer on Tru64
- incorporated Yon Derek and Igor Zlatkovic fixes and
improvementsforcompilation on Windows MSC
- update of libxml-doc.el (Felix Natter)
- fixed 2 bugs in URI normalization code
2.3.11: June 17 2001
- updates to trio, Makefiles and configure should fix
someportabilityproblems (alpha)
- fixed some HTML serialization problems (pre, script,
andblock/inlinehandling), added encoding aware APIs, cleanup of
thiscode
- added xmlHasNsProp()
- implemented a specific PI for encoding support in the
DocBookSGMLparser
- some XPath fixes (-Infinity, / as a function parameter
andnamespacesnode selection)
- fixed a performance problem and an error in the validation code
- fixed XInclude routine to implement the recursive behaviour
- fixed xmlFreeNode problem when libxml is included statically twice
- added --version to xmllint for bug reports
2.3.10: June 1 2001
- fixed the SGML catalog support
- a number of reported bugs got fixed, in XPath, iconv
detection,XIncludeprocessing
- XPath string function should now handle unicode correctly
2.3.9: May 19 2001
Lots of bugfixes, and added a basic SGML catalog support:
- HTML push bugfix #54891 and another patch from Jonas Borgstr�m
- some serious speed optimization again
- some documentation cleanups
- trying to get better linking on Solaris (-R)
- XPath API cleanup from Thomas Broyer
- Validation bug fixed #54631, added a patch from Gary
Pennington,fixedxmlValidGetValidElements()
- Added an INSTALL file
- Attribute removal added to API: #54433
- added a basic support for SGML catalogs
- fixed xmlKeepBlanksDefault(0) API
- bugfix in xmlNodeGetLang()
- fixed a small configure portability problem
- fixed an inversion of SYSTEM and PUBLIC identifier in HTML document
1.8.13: May 14 2001
- bugfixes release of the old libxml1 branch used by Gnome
2.3.8: May 3 2001
- Integrated an SGML DocBook parser for the Gnome project
- Fixed a few things in the HTML parser
- Fixed some XPath bugs raised by XSLT use, tried to fix thefloatingpoint
portability issue
- Speed improvement (8M/s for SAX, 3M/s for DOM, 1.5M/s
forDOM+validationusing the XML REC as input and a 700MHz celeron).
- incorporated more Windows cleanup
- added xmlSaveFormatFile()
- fixed problems in copying nodes with entities references (gdome)
- removed some troubles surrounding the new validation module
2.3.7: April 22 2001
- lots of small bug fixes, corrected XPointer
- Non deterministic content model validation support
- added xmlDocCopyNode for gdome2
- revamped the way the HTML parser handles end of tags
- XPath: corrections of namespaces support and number formatting
- Windows: Igor Zlatkovic patches for MSC compilation
- HTML output fixes from P C Chow and William M. Brack
- Improved validation speed sensible for DocBook
- fixed a big bug with ID declared in external parsed entities
- portability fixes, update of Trio from Bjorn Reese
2.3.6: April 8 2001
- Code cleanup using extreme gcc compiler warning options,
foundandcleared half a dozen potential problem
- the Eazel team found an XML parser bug
- cleaned up the user of some of the string formatting function.
usedthetrio library code to provide the one needed when the platform
ismissingthem
- xpath: removed a memory leak and fixed the predicate
evaluationproblem,extended the testsuite and cleaned up the result.
XPointer seemsbroken...
2.3.5: Mar 23 2001
- Biggest change is separate parsing and evaluation of
XPathexpressions,there is some new APIs for this too
- included a number of bug fixes(XML push parser,
51876,notations,52299)
- Fixed some portability issues
2.3.4: Mar 10 2001
- Fixed bugs #51860 and #51861
- Added a global variable xmlDefaultBufferSize to allow defaultbuffersize
to be application tunable.
- Some cleanup in the validation code, still a bug left and
thispartshould probably be rewritten to support ambiguous content
model:-\
- Fix a couple of serious bugs introduced or raised by changes
in2.3.3parser
- Fixed another bug in xmlNodeGetContent()
- Bjorn fixed XPath node collection and Number formatting
- Fixed a loop reported in the HTML parsing
- blank space are reported even if the Dtd content model proves
thattheyare formatting spaces, this is for XML conformance
2.3.3: Mar 1 2001
- small change in XPath for XSLT
- documentation cleanups
- fix in validation by Gary Pennington
- serious parsing performances improvements
2.3.2: Feb 24 2001
- chasing XPath bugs, found a bunch, completed some TODO
- fixed a Dtd parsing bug
- fixed a bug in xmlNodeGetContent
- ID/IDREF support partly rewritten by Gary Pennington
2.3.1: Feb 15 2001
- some XPath and HTML bug fixes for XSLT
- small extension of the hash table interfaces for
DOMgdome2implementation
- A few bug fixes
2.3.0: Feb 8 2001 (2.2.12 was on 25 Jan but I didn't kept track)
- Lots of XPath bug fixes
- Add a mode with Dtd lookup but without validation error
reportingforXSLT
- Add support for text node without escaping (XSLT)
- bug fixes for xmlCheckFilename
- validation code bug fixes from Gary Pennington
- Patch from Paul D. Smith correcting URI path normalization
- Patch to allow simultaneous install of libxml-develandlibxml2-devel
- the example Makefile is now fixed
- added HTML to the RPM packages
- tree copying bugfixes
- updates to Windows makefiles
- optimization patch from Bjorn Reese
2.2.11: Jan 4 2001
- bunch of bug fixes (memory I/O, xpath, ftp/http, ...)
- added htmlHandleOmittedElem()
- Applied Bjorn Reese's IPV6 first patch
- Applied Paul D. Smith patches for validation of XInclude results
- added XPointer xmlns() new scheme support
2.2.10: Nov 25 2000
- Fix the Windows problems of 2.2.8
- integrate OpenVMS patches
- better handling of some nasty HTML input
- Improved the XPointer implementation
- integrate a number of provided patches
2.2.9: Nov 25 2000
2.2.8: Nov 13 2000
- First version of XIncludesupport
- Patch in conditional section handling
- updated MS compiler project
- fixed some XPath problems
- added an URI escaping function
- some other bug fixes
2.2.7: Oct 31 2000
- added message redirection
- XPath improvements (thanks TOM !)
- xmlIOParseDTD() added
- various small fixes in the HTML, URI, HTTP and XPointer support
- some cleanup of the Makefile, autoconf and the distribution content
2.2.6: Oct 25 2000:
- Added an hash table module, migrated a number of internal
structuretothose
- Fixed a posteriori validation problems
- HTTP module cleanups
- HTML parser improvements (tag errors, script/style
handling,attributenormalization)
- coalescing of adjacent text nodes
- couple of XPath bug fixes, exported the internal API
2.2.5: Oct 15 2000:
- XPointer implementation and testsuite
- Lot of XPath fixes, added variable and functions
registration,moretests
- Portability fixes, lots of enhancements toward an easy Windows
buildandrelease
- Late validation fixes
- Integrated a lot of contributed patches
- added memory management docs
- a performance problem when using large buffer seems fixed
2.2.4: Oct 1 2000:
- main XPath problem fixed
- Integrated portability patches for Windows
- Serious bug fixes on the URI and HTML code
2.2.3: Sep 17 2000
- bug fixes
- cleanup of entity handling code
- overall review of all loops in the parsers, all sprintf usage
hasbeenchecked too
- Far better handling of larges Dtd. Validating against DocBook
XMLDtdworks smoothly now.
1.8.10: Sep 6 2000
- bug fix release for some Gnome projects
2.2.2: August 12 2000
- mostly bug fixes
- started adding routines to access xml parser context options
2.2.1: July 21 2000
- a purely bug fixes release
- fixed an encoding support problem when parsing from a memory block
- fixed a DOCTYPE parsing problem
- removed a bug in the function allowing to override the
memoryallocationroutines
2.2.0: July 14 2000
- applied a lot of portability fixes
- better encoding support/cleanup and saving (content is nowalwaysencoded
in UTF-8)
- the HTML parser now correctly handles encodings
- added xmlHasProp()
- fixed a serious problem with &
- propagated the fix to FTP client
- cleanup, bugfixes, etc ...
- Added a page about libxmlInternationalizationsupport
1.8.9: July 9 2000
- fixed the spec the RPMs should be better
- fixed a serious bug in the FTP implementation, released 1.8.9
tosolverpmfind users problem
2.1.1: July 1 2000
- fixes a couple of bugs in the 2.1.0 packaging
- improvements on the HTML parser
2.1.0 and 1.8.8: June 29 2000
- 1.8.8 is mostly a commodity package for upgrading to libxml2accordingto
new instructions. It fixes a nastyproblemabout
& charref parsing
- 2.1.0 also ease the upgrade from libxml v1 to the recent version.italso
contains numerous fixes and enhancements:
- added xmlStopParser() to stop parsing
- improved a lot parsing speed when there is large CDATA blocs
- includes XPath patches provided by Picdar Technology
- tried to fix as much as possible DTD validation andnamespacerelated
problems
- output to a given encoding has been added/tested
- lot of various fixes
2.0.0: Apr 12 2000
- First public release of libxml2. If you are using libxml, it's
agoodidea to check the 1.x to 2.x upgrade instructions. NOTE:
whileinitiallyscheduled for Apr 3 the release occurred only on Apr 12 due
tomassiveworkload.
- The include are now located under $prefix/include/libxml
(insteadof$prefix/include/gnome-xml), they also are referenced by
#include <libxml/xxx.h>
instead of
#include "xxx.h"
- a new URI module for parsing URIs and following strictly RFC 2396
- the memory allocation routines used by libxml can now
beoverloadeddynamically by using xmlMemSetup()
- The previously CVS only tool tester has
beenrenamedxmllintand is now installed as part of
thelibxml2package
- The I/O interface has been revamped. There is now ways to
pluginspecific I/O modules, either at the URI scheme detection
levelusingxmlRegisterInputCallbacks() or by passing I/O functions
whencreating aparser context using xmlCreateIOParserCtxt()
- there is a C preprocessor macro LIBXML_VERSION providing
theversionnumber of the libxml module in use
- a number of optional features of libxml can now be excluded
atconfiguretime (FTP/HTTP/HTML/XPath/Debug)
2.0.0beta: Mar 14 2000
- This is a first Beta release of libxml version 2
- It's available only fromxmlsoft.orgFTP, it's packaged
aslibxml2-2.0.0beta and available as tar andRPMs
- This version is now the head in the Gnome CVS base, the old
oneisavailable under the tag LIB_XML_1_X
- This includes a very large set of changes. From a programmatic
pointofview applications should not have to be modified too much, check
theupgrade page
- Some interfaces may changes (especially a bit about encoding).
- the updates includes:
- fix I18N support. ISO-Latin-x/UTF-8/UTF-16 (nearly)
seemscorrectlyhandled now
- Better handling of entities, especially well-formedness
checkingandproper PEref extensions in external subsets
- DTD conditional sections
- Validation now correctly handle entities content
- changestructuresto
accommodate DOM
- Serious progress were made toward compliance, here are the result of the
testagainsttheOASIS testsuite (except the Japanese tests since I
don't supportthatencoding yet). This URL is rebuilt every couple of hours
using theCVShead version.
1.8.7: Mar 6 2000
- This is a bug fix release:
- It is possible to disable the ignorable blanks heuristic
usedbylibxml-1.x, a new function xmlKeepBlanksDefault(0) will allow
this.Notethat for adherence to XML spec, this behaviour will be
disabledbydefault in 2.x . The same function will allow to keep
compatibilityforold code.
- Blanks in <a> </a> constructs are not
ignoredanymore,avoiding heuristic is really the Right Way :-\
- The unchecked use of snprintf which was breakinglibxml-1.8.6compilation
on some platforms has been fixed
- nanoftp.c nanohttp.c: Fixed '#' and '?' stripping
whenprocessingURIs
1.8.6: Jan 31 2000
- added a nanoFTP transport module, debugged until the new version of rpmfindcanuseit
without troubles
1.8.5: Jan 21 2000
- adding APIs to parse a well balanced chunk of XML (production [43] contentof
theXMLspec)
- fixed a hideous bug in xmlGetProp pointed by Rune.Djurhuus@fast.no
- Jody Goldberg <jgoldberg@home.com> provided another patchtryingto
solve the zlib checks problems
- The current state in gnome CVS base is expected to ship as
1.8.5withgnumeric soon
1.8.4: Jan 13 2000
- bug fixes, reintroduced xmlNewGlobalNs(), fixed xmlNewNs()
- all exit() call should have been removed from libxml
- fixed a problem with INCLUDE_WINSOCK on WIN32 platform
- added newDocFragment()
1.8.3: Jan 5 2000
- a Push interface for the XML and HTML parsers
- a shell-like interface to the document tree (try tester --shell :-)
- lots of bug fixes and improvement added over XMas holidays
- fixed the DTD parsing code to work with the xhtml DTD
- added xmlRemoveProp(), xmlRemoveID() and xmlRemoveRef()
- Fixed bugs in xmlNewNs()
- External entity loading code has been revamped, now
itusesxmlLoadExternalEntity(), some fix on entities processing
wereadded
- cleaned up WIN32 includes of socket stuff
1.8.2: Dec 21 1999
- I got another problem with includes and C++, I hope this issue
isfixedfor good this time
- Added a few tree modification
functions:xmlReplaceNode,xmlAddPrevSibling, xmlAddNextSibling,
xmlNodeSetNameandxmlDocSetRootElement
- Tried to improve the HTML output with help from Chris Lahey
1.8.1: Dec 18 1999
- various patches to avoid troubles when using libxml with
C++compilersthe "namespace" keyword and C escaping in include files
- a problem in one of the core macros IS_CHAR was corrected
- fixed a bug introduced in 1.8.0 breaking default
namespaceprocessing,and more specifically the Dia application
- fixed a posteriori validation (validation after parsing, or by
usingaDtd not specified in the original document)
- fixed a bug in
1.8.0: Dec 12 1999
- cleanup, especially memory wise
- the parser should be more reliable, especially the HTML one,
itshouldnot crash, whatever the input !
- Integrated various patches, especially a speedup improvement
forlargedataset from CarlNygard,configure with
--with-buffers to enable them.
- attribute normalization, oops should have been added long ago !
- attributes defaulted from DTDs should be available, xmlSetProp()nowdoes
entities escaping by default.
1.7.4: Oct 25 1999
- Lots of HTML improvement
- Fixed some errors when saving both XML and HTML
- More examples, the regression tests should now look clean
- Fixed a bug with contiguous charref
1.7.3: Sep 29 1999
- portability problems fixed
- snprintf was used unconditionally, leading to link problems
onsystemwere it's not available, fixed
1.7.1: Sep 24 1999
- The basic type for strings manipulated by libxml has been
renamedin1.7.1 from CHARto xmlChar.
Thereasonis that CHAR was conflicting with a predefined type on
Windows.Howeveron non WIN32 environment, compatibility is provided by the
way ofa#define .
- Changed another error : the use of a structure field called
errno,andleading to troubles on platforms where it's a macro
1.7.0: Sep 23 1999
- Added the ability to fetch remote DTD or parsed entities, see the nanohttpmodule.
- Added an errno to report errors by another mean than a simpleprintflike
callback
- Finished ID/IDREF support and checking when validation
- Serious memory leaks fixed (there is now a memory wrappermodule)
- Improvement of XPathimplementation
- Added an HTML parser front-end
XML is astandardformarkup-based
structured documents. Here is an example
XMLdocument:
<?xml version="1.0"?>
<EXAMPLE prop1="gnome is great" prop2="& linux too">
<head>
<title>Welcome to Gnome</title>
</head>
<chapter>
<title>The Linux adventure</title>
<p>bla bla bla ...</p>
<image href="linus.gif"/>
<p>...</p>
</chapter>
</EXAMPLE>
The first line specifies that it is an XML document and
givesusefulinformation about its encoding. Then the rest of the document is
atextformat whose structure is specified by tags between
brackets.Eachtag opened has to be closed. XML is pedantic
about this.However, ifa tag is empty (no content), a single tag can serve as
both theopening andclosing tag if it ends with />rather
thanwith>. Note that, for example, the image tag has no
content(justan attribute) and is closed by ending the tag
with/>.
XML can be applied successfully to a wide range of tasks, ranging
fromlongterm structured document maintenance (where it follows the steps
ofSGML) tosimple data encoding mechanisms like configuration file
formatting(glade),spreadsheets (gnumeric), or even shorter lived documents
such asWebDAV whereit is used to encode remote calls between a client and
aserver.
Check the separate libxslt page
XSL Transformations, is
alanguagefor transforming XML documents into other XML documents
(orHTML/textualoutput).
A separate library called libxslt is available implementing
XSLT-1.0forlibxml2. This module "libxslt" too can be found in the Gnome CVS
base.
You can check the progresses on the libxslt Changelog.
There are a number of language bindings and wrappers available
forlibxml2,the list below is not exhaustive. Please contact the xml-bindings@gnome.org(archives) inorder
toget updates to this list or to discuss the specific topic of
libxml2orlibxslt wrappers or bindings:
The distribution includes a set of Python bindings, which are
guaranteedtobe maintained as part of the library in the future, though
thePythoninterface have not yet reached the completeness of the C API.
Note that some of the Python purist dislike the default set
ofPythonbindings, rather than complaining I suggest they have a look at lxml the more pythonic bindings
forlibxml2and libxsltand helpMartijnFaassencomplete
those.
St�phaneBidoulmaintains aWindows portof the Python
bindings.
Note to people interested in building bindings, the API is formalized asan XML API description filewhich allows
toautomatea large part of the Python bindings, this includes
functiondescriptions,enums, structures, typedefs, etc... The Python script
used tobuild thebindings is python/generator.py in the source
distribution.
To install the Python bindings there are 2 options:
- If you use an RPM based distribution, simply install the libxml2-pythonRPM(andif
needed the libxslt-pythonRPM).
- Otherwise use the libxml2-pythonmoduledistributioncorresponding
to your installed version oflibxml2 andlibxslt. Note that to install it
you will need both libxml2and libxsltinstalled and run "python setup.py
build install" in themodule tree.
The distribution includes a set of examples and regression tests
forthepython bindings in the python/testsdirectory. Here
aresomeexcerpts from those tests:
tst.py:
This is a basic test of the file interface and DOM navigation:
import libxml2, sys
doc = libxml2.parseFile("tst.xml")
if doc.name != "tst.xml":
print "doc.name failed"
sys.exit(1)
root = doc.children
if root.name != "doc":
print "root.name failed"
sys.exit(1)
child = root.children
if child.name != "foo":
print "child.name failed"
sys.exit(1)
doc.freeDoc()
The Python module is called libxml2; parseFile is the
equivalentofxmlParseFile (most of the bindings are automatically generated,
and thexmlprefix is removed and the casing convention are kept). All node
seen atthebinding level share the same subset of accessors:
name: returns the node nametype: returns a string indicating the node typecontent: returns the content of the node, it is
basedonxmlNodeGetContent() and hence is recursive.parent,
children,last,next,
prev,doc,properties: pointing to
the associatedelement in the tree,those may return None in case no such
linkexists.
Also note the need to explicitly deallocate documents with
freeDoc().Reference counting for libxml2 trees would need quite a lot of
worktofunction properly, and rather than risk memory leaks if
notimplementedcorrectly it sounds safer to have an explicit function to free
atree. Thewrapper python objects like doc, root or child are
themautomatically garbagecollected.
validate.py:
This test check the validation interfaces and redirection
oferrormessages:
import libxml2
#deactivate error messages from the validation
def noerr(ctx, str):
pass
libxml2.registerErrorHandler(noerr, None)
ctxt = libxml2.createFileParserCtxt("invalid.xml")
ctxt.validate(1)
ctxt.parseDocument()
doc = ctxt.doc()
valid = ctxt.isValid()
doc.freeDoc()
if valid != 0:
print "validity check failed"
The first thing to notice is the call to registerErrorHandler(),
itdefinesa new error handler global to the library. It is used to avoid
seeingtheerror messages when trying to validate the invalid document.
The main interest of that test is the creation of a parser
contextwithcreateFileParserCtxt() and how the behaviour can be changed
beforecallingparseDocument() . Similarly the informations resulting from
theparsing phaseare also available using context methods.
Contexts like nodes are defined as class and the libxml2 wrappers mapstheC
function interfaces in terms of objects method as much as possible.Thebest to
get a complete view of what methods are supported is to look atthelibxml2.py
module containing all the wrappers.
push.py:
This test show how to activate the push parser interface:
import libxml2
ctxt = libxml2.createPushParser(None, "<foo", 4, "test.xml")
ctxt.parseChunk("/>", 2, 1)
doc = ctxt.doc()
doc.freeDoc()
The context is created with a special call based
onthexmlCreatePushParser() from the C library. The first argument is
anoptionalSAX callback object, then the initial set of data, the length and
thename ofthe resource in case URI-References need to be computed by
theparser.
Then the data are pushed using the parseChunk() method, the
lastcallsetting the third argument terminate to 1.
pushSAX.py:
this test show the use of the event based parsing interfaces. In
thiscasethe parser does not build a document, but provides callback
informationasthe parser makes progresses analyzing the data being
provided:
import libxml2
log = ""
class callback:
def startDocument(self):
global log
log = log + "startDocument:"
def endDocument(self):
global log
log = log + "endDocument:"
def startElement(self, tag, attrs):
global log
log = log + "startElement %s %s:" % (tag, attrs)
def endElement(self, tag):
global log
log = log + "endElement %s:" % (tag)
def characters(self, data):
global log
log = log + "characters: %s:" % (data)
def warning(self, msg):
global log
log = log + "warning: %s:" % (msg)
def error(self, msg):
global log
log = log + "error: %s:" % (msg)
def fatalError(self, msg):
global log
log = log + "fatalError: %s:" % (msg)
handler = callback()
ctxt = libxml2.createPushParser(handler, "<foo", 4, "test.xml")
chunk = " url='tst'>b"
ctxt.parseChunk(chunk, len(chunk), 0)
chunk = "ar</foo>"
ctxt.parseChunk(chunk, len(chunk), 1)
reference = "startDocument:startElement foo {'url': 'tst'}:" + \
"characters: bar:endElement foo:endDocument:"
if log != reference:
print "Error got: %s" % log
print "Expected: %s" % reference
The key object in that test is the handler, it provides a number
ofentrypoints which can be called by the parser as it makes progresses
toindicatethe information set obtained. The full set of callback is larger
thanwhatthe callback class in that specific example implements (see
theSAXdefinition for a complete list). The wrapper will only call those
suppliedbythe object when activated. The startElement receives the names of
theelementand a dictionary containing the attributes carried by this
element.
Also note that the reference string generated from the callback
showsasingle character call even though the string "bar" is passed to
theparserfrom 2 different call to parseChunk()
xpath.py:
This is a basic test of XPath wrappers support
import libxml2
doc = libxml2.parseFile("tst.xml")
ctxt = doc.xpathNewContext()
res = ctxt.xpathEval("//*")
if len(res) != 2:
print "xpath query: wrong node set size"
sys.exit(1)
if res[0].name != "doc" or res[1].name != "foo":
print "xpath query: wrong node set value"
sys.exit(1)
doc.freeDoc()
ctxt.xpathFreeContext()
This test parses a file, then create an XPath context to
evaluateXPathexpression on it. The xpathEval() method execute an XPath query
andreturnsthe result mapped in a Python way. String and numbers are
nativelyconverted,and node sets are returned as a tuple of libxml2 Python
nodeswrappers. Likethe document, the XPath context need to be freed
explicitly,also not thatthe result of the XPath query may point back to the
documenttree and hencethe document must be freed after the result of the
query isused.
xpathext.py:
This test shows how to extend the XPath engine with functions
writteninpython:
import libxml2
def foo(ctx, x):
return x + 1
doc = libxml2.parseFile("tst.xml")
ctxt = doc.xpathNewContext()
libxml2.registerXPathFunction(ctxt._o, "foo", None, foo)
res = ctxt.xpathEval("foo(1)")
if res != 2:
print "xpath extension failure"
doc.freeDoc()
ctxt.xpathFreeContext()
Note how the extension function is registered with the context
(butthatpart is not yet finalized, this may change slightly in the
future).
tstxpath.py:
This test is similar to the previous one but shows how
theextensionfunction can access the XPath evaluation context:
def foo(ctx, x):
global called
#
# test that access to the XPath evaluation contexts
#
pctxt = libxml2.xpathParserContext(_obj=ctx)
ctxt = pctxt.context()
called = ctxt.function()
return x + 1
All the interfaces around the XPath parser(or rather evaluation)contextare
not finalized, but it should be sufficient to do contextual workat
theevaluation point.
Memory debugging:
last but not least, all tests starts with the following prologue:
#memory debug specific
libxml2.debugMemory(1)
and ends with the following epilogue:
#memory debug specific
libxml2.cleanupParser()
if libxml2.debugMemory(1) == 0:
print "OK"
else:
print "Memory leak %d bytes" % (libxml2.debugMemory(1))
libxml2.dumpMemory()
Those activate the memory debugging interface of libxml2 whereallallocated
block in the library are tracked. The prologue then cleans upthelibrary state
and checks that all allocated memory has been freed. If notitcalls
dumpMemory() which saves that list in a .memdumpfile.
Libxml2 is made of multiple components; some of them are optional,
andmostof the block interfaces are public. The main components are:
- an Input/Output layer
- FTP and HTTP client layers (optional)
- an Internationalization layer managing the encodings support
- a URI module
- the XML parser and its basic SAX interface
- an HTML parser using the same SAX interface (optional)
- a SAX tree module to build an in-memory DOM representation
- a tree module to manipulate the DOM representation
- a validation module using the DOM representation (optional)
- an XPath module for global lookup in a DOM representation(optional)
- a debug module (optional)
Graphically this gives the following:
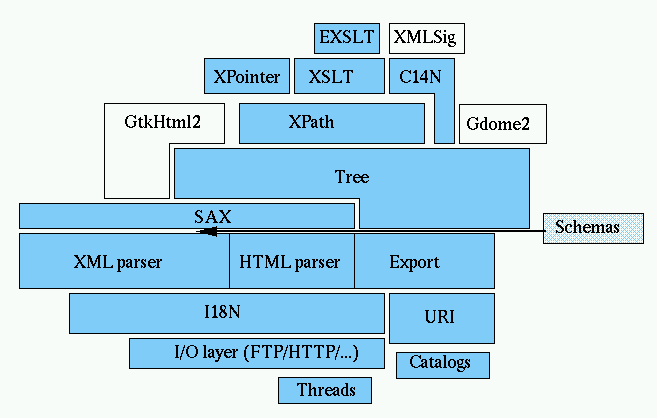
The parser returns a tree built during the document analysis.
Thevaluereturned is an xmlDocPtr(i.e., a pointer
toanxmlDocstructure). This structure contains
informationsuchas the file name, the document type, and
achildrenpointerwhich is the root of the document (or
moreexactly the first child under theroot which is the document). The tree
ismade of xmlNodes,chained in double-linked lists of
siblingsand with a children<->parentrelationship. An xmlNode can also
carryproperties (a chain of xmlAttrstructures). An attribute may have a
valuewhich is a list of TEXT orENTITY_REF nodes.
Here is an example (erroneous with respect to the XML spec
sincethereshould be only one ELEMENT under the root):
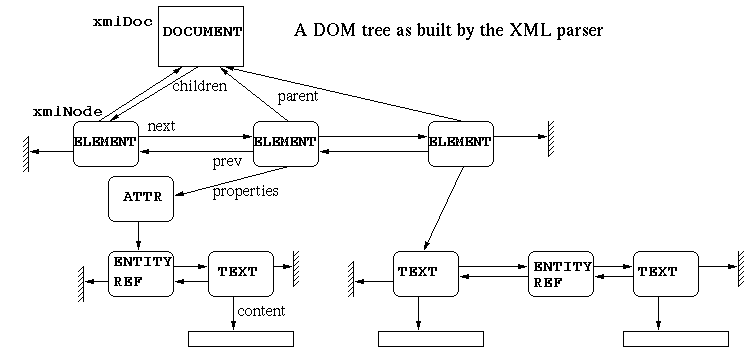
In the source package there is a small program (not installed
bydefault)called xmllintwhich parses XML files given
asargument andprints them back as parsed. This is useful for detecting
errorsboth in XMLcode and in the XML parser itself. It has an
option--debugwhich prints the actual in-memory structure of
thedocument; here is theresult with the examplegivenbefore:
DOCUMENT
version=1.0
standalone=true
ELEMENT EXAMPLE
ATTRIBUTE prop1
TEXT
content=gnome is great
ATTRIBUTE prop2
ENTITY_REF
TEXT
content= linux too
ELEMENT head
ELEMENT title
TEXT
content=Welcome to Gnome
ELEMENT chapter
ELEMENT title
TEXT
content=The Linux adventure
ELEMENT p
TEXT
content=bla bla bla ...
ELEMENT image
ATTRIBUTE href
TEXT
content=linus.gif
ELEMENT p
TEXT
content=...
This should be useful for learning the internal representation model.
Sometimes the DOM tree output is just too large to fit
reasonablyintomemory. In that case (and if you don't expect to save back the
XMLdocumentloaded using libxml), it's better to use the SAX interface of
libxml.SAX isa callback-based interfaceto the parser.
Beforeparsing,the application layer registers a customized set of callbacks
whicharecalled by the library as it progresses through the XML input.
To get more detailed step-by-step guidance on using the SAX
interfaceoflibxml, see the nicedocumentation.writtenby
JamesHenstridge.
You can debug the SAX behaviour by using
thetestSAXprogram located in the gnome-xml module (it's
usuallynot shipped in thebinary packages of libxml, but you can find it in
the tarsourcedistribution). Here is the sequence of callbacks that would be
reportedbytestSAX when parsing the example XML document shown earlier:
SAX.setDocumentLocator()
SAX.startDocument()
SAX.getEntity(amp)
SAX.startElement(EXAMPLE, prop1='gnome is great', prop2='& linux too')
SAX.characters( , 3)
SAX.startElement(head)
SAX.characters( , 4)
SAX.startElement(title)
SAX.characters(Welcome to Gnome, 16)
SAX.endElement(title)
SAX.characters( , 3)
SAX.endElement(head)
SAX.characters( , 3)
SAX.startElement(chapter)
SAX.characters( , 4)
SAX.startElement(title)
SAX.characters(The Linux adventure, 19)
SAX.endElement(title)
SAX.characters( , 4)
SAX.startElement(p)
SAX.characters(bla bla bla ..., 15)
SAX.endElement(p)
SAX.characters( , 4)
SAX.startElement(image, href='linus.gif')
SAX.endElement(image)
SAX.characters( , 4)
SAX.startElement(p)
SAX.characters(..., 3)
SAX.endElement(p)
SAX.characters( , 3)
SAX.endElement(chapter)
SAX.characters( , 1)
SAX.endElement(EXAMPLE)
SAX.endDocument()
Most of the other interfaces of libxml2 are based on the
DOMtree-buildingfacility, so nearly everything up to the end of this
documentpresupposes theuse of the standard DOM tree build. Note that the DOM
treeitself is built bya set of registered default callbacks, without
internalspecificinterface.
Table of Content:
- General overview
- The definition
- Simple rules
- How to reference a DTD from a document
- Declaring elements
- Declaring attributes
- Some examples
- How to validate
- Other resources
Well what is validation and what is a DTD ?
DTD is the acronym for Document Type Definition. This is a
descriptionofthe content for a family of XML files. This is part of the
XML1.0specification, and allows one to describe and verify that a
givendocumentinstance conforms to the set of rules detailing its structure
andcontent.
Validation is the process of checking a document against a
DTD(moregenerally against a set of construction rules).
The validation process and building DTDs are the two most difficultpartsof
the XML life cycle. Briefly a DTD defines all the possible elementsto befound
within your document, what is the formal shape of your documenttree(by
defining the allowed content of an element; either text, aregularexpression
for the allowed list of children, or mixed content i.e.both textand
children). The DTD also defines the valid attributes for allelements andthe
types of those attributes.
The W3C XML Recommendation(Tim Bray's annotated
versionofRev1):
(unfortunately) all this is inherited from the SGML world, the
syntaxisancient...
Writing DTDs can be done in many ways. The rules to build them if
youneedsomething permanent or something which can evolve over time can
beradicallydifferent. Really complex DTDs like DocBook ones are flexible
butquiteharder to design. I will just focus on DTDs for a formats with a
fixedsimplestructure. It is just a set of basic rules, and definitely
notexhaustive norusable for complex DTD design.
Assuming the top element of the document is specand the
dtdisplaced in the file mydtdin the
subdirectorydtdsofthe directory from where the document were
loaded:
<!DOCTYPE spec SYSTEM "dtds/mydtd">
Notes:
- The system string is actually an URI-Reference (as defined in RFC 2396) so you can
useafull URL string indicating the location of your DTD on the Web. This
isareally good thing to do if you want others to validate
yourdocument.
- It is also possible to associate a
PUBLICidentifier(amagic
string) so that the DTD is looked up in catalogs on the clientsidewithout
having to locate it on the web.
- A DTD contains a set of element and attribute declarations,
buttheydon't define what the root of the document should be. This
isexplicitlytold to the parser/validator as the first element
ofthe
DOCTYPEdeclaration.
The following declares an element spec:
<!ELEMENT spec (front, body, back?)>
It also expresses that the spec element contains onefront,one
bodyand one optionalbackchildren elements inthis
order. The declaration of oneelement of the structure and its contentare done
in a single declaration.Similarly the following
declaresdiv1elements:
<!ELEMENT div1 (head, (p | list | note)*, div2?)>
which means div1 contains one headthen a series
ofoptionalp, lists and notes and
thenanoptional div2. And last but not least an element
cancontaintext:
<!ELEMENT b (#PCDATA)>
bcontains text or being of mixed content (text and
elementsinno particular order):
<!ELEMENT p (#PCDATA|a|ul|b|i|em)*>
p can contain text or
a,ul,b, i or
emelements inno particularorder.
Again the attributes declaration includes their content definition:
<!ATTLIST termdef name CDATA #IMPLIED>
means that the element termdefcan have
anameattribute containing text (CDATA) and which
isoptional(#IMPLIED). The attribute value can also be
definedwithin aset:
<!ATTLIST list
type(bullets|ordered|glossary)"ordered">
means listelement have a typeattribute
with3allowed values "bullets", "ordered" or "glossary" and which
defaultto"ordered" if the attribute is not explicitly specified.
The content type of an attribute can be
text(CDATA),anchor/reference/references(ID/IDREF/IDREFS),entity(ies)(ENTITY/ENTITIES)
orname(s)(NMTOKEN/NMTOKENS). The following
definesthat achapterelement can have an
optionalidattributeof type ID, usable for reference
fromattribute of typeIDREF:
<!ATTLIST chapter id ID #IMPLIED>
The last value of an attribute definition can
be#REQUIREDmeaning that the attribute has to be
given,#IMPLIEDmeaning that it is optional, or the default
value(possibly prefixed by#FIXEDif it is the only allowed).
Notes:
The directory test/valid/dtds/in the
libxml2distributioncontains some complex DTD examples. The example in
thefiletest/valid/dia.xmlshows an XML file where the simple
DTDisdirectly included within the document.
The simplest way is to use the xmllint program included with
libxml.The--validoption turns-on validation of the files given
asinput.For example the following validates a copy of the first revision of
theXML1.0 specification:
xmllint --valid --noout test/valid/REC-xml-19980210.xml
the -- noout is used to disable output of the resulting tree.
The --dtdvalid dtdallows validation of the
document(s)againsta given DTD.
Libxml2 exports an API to handle DTDs and validation, check the associateddescription.
DTDs are as old as SGML. So there may be a number of examples
on-line,Iwill just list one for now, others pointers welcome:
I suggest looking at the examples found under test/valid/dtd and any
ofthelarge number of books available on XML. The dia example in
test/validshouldbe both simple and complete enough to allow you to build your
own.
Table of Content:
- General overview
- Setting libxml2 set of memory routines
- Cleaning up after parsing
- Debugging routines
- General memory requirements
The module xmlmemory.hprovidesthe
interfaces to the libxml2 memory system:
- libxml2 does not use the libc memory allocator directly
butxmlFree(),xmlMalloc() and xmlRealloc()
- those routines can be reallocated to a specific set of
routine,bydefault the libc ones i.e. free(), malloc() and realloc()
- the xmlmemory.c module includes a set of debugging routine
It is sometimes useful to not use the default memory allocator,
eitherfordebugging, analysis or to implement a specific behaviour on
memorymanagement(like on embedded systems). Two function calls are available
to doso:
- xmlMemGet()whichreturn
the current set of functions in use by the parser
- xmlMemSetup()whichallow
to set up a new set of memory allocation functions
Of course a call to xmlMemSetup() should probably be done beforecallingany
other libxml2 routines (unless you are sure your allocationsroutines
arecompatibles).
Libxml2 is not stateless, there is a few set of memory
structuresneedingallocation before the parser is fully functional (some
encodingstructuresfor example). This also mean that once parsing is finished
there isa tinyamount of memory (a few hundred bytes) which can be recollected
if youdon'treuse the parser immediately:
- xmlCleanupParser()isa
centralized routine to free the parsing states. Note that
itwon'tdeallocate any produced tree if any (use the xmlFreeDoc()
andrelatedroutines for this).
- xmlInitParser()isthe
dual routine allowing to preallocate the parsing statewhich can beuseful
for example to avoid initialization reentrancyproblems when usinglibxml2
in multithreaded applications
Generally xmlCleanupParser() is safe, if needed the state will berebuildat
the next invocation of parser routines, but be careful of theconsequencesin
multithreaded applications.
When configured using --with-mem-debug flag (off by default), libxml2usesa
set of memory allocation debugging routines keeping track of
allallocatedblocks and the location in the code where the routine was called.
Acouple ofother debugging routines allow to dump the memory allocated infos
toa fileor call a specific routine when a given block number is allocated:
When developing libxml2 memory debug is enabled, the tests
programscallxmlMemoryDump () and the "make test" regression tests will check
foranymemory leak during the full regression test sequence, this helps
alotensuring that libxml2 does not leak memory and bullet
proofmemoryallocations use (some libc implementations are known to be far
toopermissiveresulting in major portability problems!).
If the .memdump reports a leak, it displays the allocation functionandalso
tries to give some informations about the content and structure
oftheallocated blocks left. This is sufficient in most cases to find
theculprit,but not always. Assuming the allocation problem is reproducible,
itispossible to find more easily:
- write down the block number xxxx not allocated
- export the environment variable XML_MEM_BREAKPOINT=xxxx ,
theeasiestwhen using GDB is to simply give the command
set environment XML_MEM_BREAKPOINT xxxx
before running the program.
- run the program under a debugger and set a
breakpointonxmlMallocBreakpoint() a specific function called when this
preciseblockis allocated
- when the breakpoint is reached you can then do a fine analysis
oftheallocation an step to see the condition resulting in
themissingdeallocation.
I used to use a commercial tool to debug libxml2 memory problems
butafternoticing that it was not detecting memory leaks that simple
mechanismwasused and proved extremely efficient until now. Lately I have also
used valgrindwith quite
somesuccess,it is tied to the i386 architecture since it works by emulating
theprocessorand instruction set, it is slow but extremely efficient, i.e.
itspot memoryusage errors in a very precise way.
How much libxml2 memory require ? It's hard to tell in average itdependsof
a number of things:
- the parser itself should work in a fixed amount of memory,
exceptforinformation maintained about the stacks of names and
entitieslocations.The I/O and encoding handlers will probably account for
a fewKBytes.This is true for both the XML and HTML parser (though the
HTMLparserneed more state).
- If you are generating the DOM tree then memory requirements
willgrownearly linear with the size of the data. In general for
abalancedtextual document the internal memory requirement is about 4
timesthesize of the UTF8 serialization of this document (example
theXML-1.0recommendation is a bit more of 150KBytes and takes 650KBytes
ofmainmemory when parsed). Validation will add a amount of memory
requiredformaintaining the external Dtd state which should be linear
withthecomplexity of the content model defined by the Dtd
- If you need to work with fixed memory requirements or don't needthefull
DOM tree then using the xmlReaderinterfaceis
probably the best way toproceed, it still allows tovalidate or operate on
subset of the tree ifneeded.
- If you don't care about the advanced features of libxml2likevalidation,
DOM, XPath or XPointer, don't use entities, need to workwithfixed memory
requirements, and try to get the fastest parsingpossiblethen the SAX
interface should be used, but it has knownrestrictions.
If you are not really familiar with Internationalization (usual
shortcutisI18N) , Unicode, characters and glyphs, I suggest you read a presentationbyTim
Bray on Unicode and why you should care about it.
If you don't understand why it does not make sense to have
astringwithout knowing what encoding it uses, then as Joel Spolsky said
please do
notwriteanother line of code until you finish reading that article.. It
isaprerequisite to understand this page, and avoid a lot of
problemswithlibxml2, XML or text processing in general.
Table of Content:
- What does internationalization
supportmean?
- The internal encoding,
howandwhy
- How is it implemented ?
- Default supported encodings
- How to extend theexistingsupport
XML was designed from the start to allow the support of any charactersetby
using Unicode. Any conformant XML parser has to support the UTF-8andUTF-16
default encodings which can both express the full unicode ranges.UTF8is a
variable length encoding whose greatest points are to reuse thesameencoding
for ASCII and to save space for Western encodings, but it is abitmore complex
to handle in practice. UTF-16 use 2 bytes per character(andsometimes combines
two pairs), it makes implementation easier, but looksabit overkill for
Western languages encoding. Moreover the XMLspecificationallows the document
to be encoded in other encodings at thecondition thatthey are clearly labeled
as such. For example the following isa wellformedXML document encoded in
ISO-8859-1 and using accentuated lettersthat weFrench like for both markup
and content:
<?xml version="1.0" encoding="ISO-8859-1"?>
<tr�s>l�</tr�s>
Having internationalization support in libxml2 means the following:
- the document is properly parsed
- informations about it's encoding are saved
- it can be modified
- it can be saved in its original encoding
- it can also be saved in another encoding supported by
libxml2(forexample straight UTF8 or even an ASCII form)
Another very important point is that the whole libxml2 API,
withtheexception of a few routines to read with a specific encoding or save
toaspecific encoding, is completely agnostic about the original encoding
ofthedocument.
It should be noted too that the HTML parser embedded in libxml2 nowobeythe
same rules too, the following document will be (as of 2.2.2) handledinan
internationalized fashion by libxml2 too:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"
"http://www.w3.org/TR/REC-html40/loose.dtd">
<html lang="fr">
<head>
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=ISO-8859-1">
</head>
<body>
<p>W3C cr�e des standards pour le Web.</body>
</html>
One of the core decisions was to force all documents to be converted
toadefault internal encoding, and that encoding to be UTF-8, here
aretherationales for those choices:
- keeping the native encoding in the internal form would force
thelibxmlusers (or the code associated) to be fully aware of the encoding
oftheoriginal document, for examples when adding a text node to
adocument,the content would have to be provided in the document
encoding,i.e. theclient code would have to check it before hand, make
sure it'sconformantto the encoding, etc ... Very hard in practice, though
in somespecificcases this may make sense.
- the second decision was which encoding. From the XML spec only
UTF8andUTF16 really makes sense as being the two only encodings for
whichthereis mandatory support. UCS-4 (32 bits fixed size encoding)
couldbeconsidered an intelligent choice too since it's a direct
Unicodemappingsupport. I selected UTF-8 on the basis of efficiency
andcompatibilitywith surrounding software:
- UTF-8 while a bit more complex to convert from/to (i.e.slightlymore
costly to import and export CPU wise) is also far morecompactthan
UTF-16 (and UCS-4) for a majority of the documents I seeit usedfor
right now (RPM RDF catalogs, advogato data, variousconfigurationfile
formats, etc.) and the key point for today'scomputerarchitecture is
efficient uses of caches. If one nearlydouble thememory requirement
to store the same amount of data, thiswill trashcaches (main
memory/external caches/internal caches) and mytake isthat this harms
the system far more than the CPU requirementsneededfor the conversion
to UTF-8
- Most of libxml2 version 1 users were using it with
straightASCIImost of the time, doing the conversion with an
internalencodingrequiring all their code to be rewritten was a
seriousshow-stopperfor using UTF-16 or UCS-4.
- UTF-8 is being used as the de-facto internal encoding
standardforrelated code like the pangoupcoming Gnome text widget,
anda lot of Unix code (yet another placewhere Unix programmer base
takesa different approach from Microsoft- they are using UTF-16)
What does this mean in practice for the libxml2 user:
- xmlChar, the libxml2 data type is a byte, those bytes must
beassembledas UTF-8 valid strings. The proper way to terminate an xmlChar
*stringis simply to append 0 byte, as usual.
- One just need to make sure that when using chars outside the
ASCIIset,the values has been properly converted to UTF-8
Let's describe how all this works within libxml, basically
theI18N(internationalization) support get triggered only during I/O
operation,i.e.when reading a document or saving one. Let's look first at
thereadingsequence:
- when a document is processed, we usually don't know the
encoding,asimple heuristic allows to detect UTF-16 and UCS-4 from
encodingswherethe ASCII range (0-0x7F) maps with ASCII
- the xml declaration if available is parsed, including
theencodingdeclaration. At that point, if the autodetected encoding
isdifferentfrom the one declared a call to xmlSwitchEncoding()
isissued.
- If there is no encoding declaration, then the input has to be
ineitherUTF-8 or UTF-16, if it is not then at some point when
processingtheinput, the converter/checker of UTF-8 form will raise an
encodingerror.You may end-up with a garbled document, or no document at
all !Example:
~/XML -> ./xmllint err.xml
err.xml:1: error: Input is not proper UTF-8, indicate encoding !
<tr�s>l�</tr�s>
^
err.xml:1: error: Bytes: 0xE8 0x73 0x3E 0x6C
<tr�s>l�</tr�s>
^
- xmlSwitchEncoding() does an encoding name lookup, canonicalize
it,andthen search the default registered encoding converters for
thatencoding.If it's not within the default set and iconv() support has
beencompiledit, it will ask iconv for such an encoder. If this fails then
theparserwill report an error and stops processing:
~/XML -> ./xmllint err2.xml
err2.xml:1: error: Unsupported encoding UnsupportedEnc
<?xml version="1.0" encoding="UnsupportedEnc"?>
^
- From that point the encoder processes progressively the input
(itisplugged as a front-end to the I/O module) for that entity.
Itcapturesand converts on-the-fly the document to be parsed to UTF-8.
Theparseritself just does UTF-8 checking of this input and
processittransparently. The only difference is that the encoding
informationhasbeen added to the parsing context (more precisely to
theinputcorresponding to this entity).
- The result (when using DOM) is an internal form completely in
UTF-8withjust an encoding information on the document node.
Ok then what happens when saving the document (assuming
youcollected/builtan xmlDoc DOM like structure) ? It depends on the
functioncalled,xmlSaveFile() will just try to save in the original
encoding,whilexmlSaveFileTo() and xmlSaveFileEnc() can optionally save to
agivenencoding:
- if no encoding is given, libxml2 will look for an
encodingvalueassociated to the document and if it exists will try to save
tothatencoding,
otherwise everything is written in the internal form, i.e. UTF-8
- so if an encoding was specified, either at the API level or
onthedocument, libxml2 will again canonicalize the encoding name,
lookupfor aconverter in the registered set or through iconv. If not
foundthefunction will return an error code
- the converter is placed before the I/O buffer layer, as another
kindofbuffer, then libxml2 will simply push the UTF-8 serialization
tothroughthat buffer, which will then progressively be converted and
pushedontothe I/O layer.
- It is possible that the converter code fails on some input,
forexampletrying to push an UTF-8 encoded Chinese character through
theUTF-8 toISO-8859-1 converter won't work. Since the encoders
areprogressive theywill just report the error and the number of
bytesconverted, at thatpoint libxml2 will decode the offending
character,remove it from thebuffer and replace it with the associated
charRefencoding { andresume the conversion. This guarantees that
anydocument will be savedwithout losses (except for markup names where
thisis not legal, this isa problem in the current version, in practice
avoidusing non-asciicharacters for tag or attribute names). A special
"ascii"encoding nameis used to save documents to a pure ascii form can be
usedwhenportability is really crucial
Here are a few examples based on the same test document:
~/XML -> ./xmllint isolat1
<?xml version="1.0" encoding="ISO-8859-1"?>
<tr�s>l�</tr�s>
~/XML -> ./xmllint --encode UTF-8 isolat1
<?xml version="1.0" encoding="UTF-8"?>
<très>l� �</très>
~/XML ->
The same processing is applied (and reuse most of the code) for
HTMLI18Nprocessing. Looking up and modifying the content encoding is a
bitmoredifficult since it is located in a <meta> tag under
the<head>,so a couple of functions htmlGetMetaEncoding()
andhtmlSetMetaEncoding() havebeen provided. The parser also attempts to
switchencoding on the fly whendetecting such a tag on input. Except for that
theprocessing is the same(and again reuses the same code).
libxml2 has a set of default converters for the followingencodings(located
in encoding.c):
- UTF-8 is supported by default (null handlers)
- UTF-16, both little and big endian
- ISO-Latin-1 (ISO-8859-1) covering most western languages
- ASCII, useful mostly for saving
- HTML, a specific handler for the conversion of UTF-8 to ASCII
withHTMLpredefined entities like © for the Copyright sign.
More over when compiled on an Unix platform with iconv support the
fullsetof encodings supported by iconv can be instantly be used by libxml. On
alinuxmachine with glibc-2.1 the list of supported encodings and aliases
fill3 fullpages, and include UCS-4, the full set of ISO-Latin encodings, and
thevariousJapanese ones.
To convert from the UTF-8 values returned from the API to
anotherencodingthen it is possible to use the function provided from the encoding modulelike UTF8Toisolat1, or
usethePOSIX iconv()APIdirectly.
Encoding aliases
From 2.2.3, libxml2 has support to register encoding names aliases.Thegoal
is to be able to parse document whose encoding is supported butwherethe name
differs (for example from the default set of names acceptedbyiconv). The
following functions allow to register and handle new aliasesforexisting
encodings. Once registered libxml2 will automatically lookupthealiases when
handling a document:
- int xmlAddEncodingAlias(const char *name, const char *alias);
- int xmlDelEncodingAlias(const char *alias);
- const char * xmlGetEncodingAlias(const char *alias);
- void xmlCleanupEncodingAliases(void);
Well adding support for new encoding, or overriding one of
theencoders(assuming it is buggy) should not be hard, just write input
andoutputconversion routines to/from UTF-8, and register
themusingxmlNewCharEncodingHandler(name, xxxToUTF8, UTF8Toxxx), and they
willbecalled automatically if the parser(s) encounter such an
encodingname(register it uppercase, this will help). The description of
theencoders,their arguments and expected return values are described in
theencoding.hheader.
Table of Content:
- General overview
- The basic buffer type
- Input I/O handlers
- Output I/O handlers
- The entities loader
- Example of customized I/O
The module xmlIO.hprovidestheinterfaces
to the libxml2 I/O system. This consists of 4 main parts:
The general mechanism used when loading
http://rpmfind.net/xml.htmlforexample in the HTML parser is the following:
- The default entity loader
calls
xmlNewInputFromFile()withthe parsing context and the
URIstring.
- the URI string is checked against the existing registered
handlersusingtheir match() callback function, if the HTTP module was
compiledin, it isregistered and its match() function will succeeds
- the open() function of the handler is called and if
successfulwillreturn an I/O Input buffer
- the parser will the start reading from this buffer
andprogressivelyfetch information from the resource, calling the
read()function of thehandler until the resource is exhausted
- if an encoding change is detected it will be installed on
theinputbuffer, providing buffering and efficient use of
theconversionroutines
- once the parser has finished, the close() function of the
handleriscalled once and the Input buffer and associated
resourcesaredeallocated.
The user defined callbacks are checked first to allow overriding
ofthedefault libxml2 I/O routines.
All the buffer manipulation handling is done
usingthexmlBuffertype define in tree.hwhich
isaresizable memory buffer. The buffer allocation strategy can be selected
tobeeither best-fit or use an exponential doubling one (CPU vs.
memoryusetrade-off). The values
areXML_BUFFER_ALLOC_EXACTandXML_BUFFER_ALLOC_DOUBLEIT,and
can be set individually or on asystem wide basis
usingxmlBufferSetAllocationScheme(). A numberof functions allows
tomanipulate buffers with names starting
withthexmlBuffer...prefix.
An Input I/O handler is a
simplestructurexmlParserInputBuffercontaining a context
associated totheresource (file descriptor, or pointer to a protocol handler),
the read()andclose() callbacks to use and an xmlBuffer. And extra xmlBuffer
and acharsetencoding handler are also present to support charset
conversionwhenneeded.
An Output handler xmlOutputBufferis completely similar
toanInput one except the callbacks are write() and close().
The entity loader resolves requests for new entities and create
inputsforthe parser. Creating an input from a filename or an URI string
isdonethrough the xmlNewInputFromFile() routine. The default entity loader
donothandle the PUBLIC identifier associated with an entity (if any). So
itjustcalls xmlNewInputFromFile() with the SYSTEM identifier (which
ismandatory inXML).
If you want to hook up a catalog mechanism then you simply need
tooverridethe default entity loader, here is an example:
#include <libxml/xmlIO.h>
xmlExternalEntityLoader defaultLoader = NULL;
xmlParserInputPtr
xmlMyExternalEntityLoader(const char *URL, const char *ID,
xmlParserCtxtPtr ctxt) {
xmlParserInputPtr ret;
const char *fileID = NULL;
/* lookup for the fileID depending on ID */
ret = xmlNewInputFromFile(ctxt, fileID);
if (ret != NULL)
return(ret);
if (defaultLoader != NULL)
ret = defaultLoader(URL, ID, ctxt);
return(ret);
}
int main(..) {
...
/*
* Install our own entity loader
*/
defaultLoader = xmlGetExternalEntityLoader();
xmlSetExternalEntityLoader(xmlMyExternalEntityLoader);
...
}
This example come from areal use case,xmlDocDump()
closes the FILE * passed by the applicationand this was aproblem. The solutionwasto redefine anew
output handler with the closing call deactivated:
- First define a new I/O output allocator where the output don't
closethefile:
xmlOutputBufferPtr
xmlOutputBufferCreateOwn(FILE *file, xmlCharEncodingHandlerPtr encoder) {
����xmlOutputBufferPtr ret;
����
����if (xmlOutputCallbackInitialized == 0)
��������xmlRegisterDefaultOutputCallbacks();
����if (file == NULL) return(NULL);
����ret = xmlAllocOutputBuffer(encoder);
����if (ret != NULL) {
��������ret->context = file;
��������ret->writecallback = xmlFileWrite;
��������ret->closecallback = NULL; /* No close callback */
����}
����return(ret);
}
- And then use it to save the document:
FILE *f;
xmlOutputBufferPtr output;
xmlDocPtr doc;
int res;
f = ...
doc = ....
output = xmlOutputBufferCreateOwn(f, NULL);
res = xmlSaveFileTo(output, doc, NULL);
Table of Content:
- General overview
- The definition
- Using catalogs
- Some examples
- How to tune catalog usage
- How to debug catalog processing
- How to create and maintain catalogs
- The implementor corner quick review
oftheAPI
- Other resources
What is a catalog? Basically it's a lookup mechanism used when an
entity(afile or a remote resource) references another entity. The catalog
lookupisinserted between the moment the reference is recognized by the
software(XMLparser, stylesheet processing, or even images referenced for
inclusionin arendering) and the time where loading that resource is
actuallystarted.
It is basically used for 3 things:
- mapping from "logical" names, the public identifiers and a
moreconcretename usable for download (and URI). For example it can
associatethelogical name
"-//OASIS//DTD DocBook XML V4.1.2//EN"
of the DocBook 4.1.2 XML DTD with the actual URL where it
canbedownloaded
http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd
- remapping from a given URL to another one, like an
HTTPindirectionsaying that
"http://www.oasis-open.org/committes/tr.xsl"
should really be looked at
"http://www.oasis-open.org/committes/entity/stylesheets/base/tr.xsl"
- providing a local cache mechanism allowing to load
theentitiesassociated to public identifiers or remote resources, this is
areallyimportant feature for any significant deployment of XML or
SGMLsince itallows to avoid the aleas and delays associated to
fetchingremoteresources.
Libxml, as of 2.4.3 implements 2 kind of catalogs:
- the older SGML catalogs, the official spec is SGML
OpenTechnicalResolution TR9401:1997, but is better understood by reading
the SP
CatalogpagefromJames Clark. This is relatively old and not the
preferredmode ofoperation of libxml.
- XMLCatalogsisfar
more flexible, more recent, uses an XML syntax andshould scale
quitebetter. This is the default option of libxml.
In a normal environment libxml2 will by default check the presence
ofacatalog in /etc/xml/catalog, and assuming it has been
correctlypopulated,the processing is completely transparent to the document
user. Totake aconcrete example, suppose you are authoring a DocBook document,
thisonestarts with the following DOCTYPE definition:
<?xml version='1.0'?>
<!DOCTYPE book PUBLIC "-//Norman Walsh//DTD DocBk XML V3.1.4//EN"
"http://nwalsh.com/docbook/xml/3.1.4/db3xml.dtd">
When validating the document with libxml, the catalog will
beautomaticallyconsulted to lookup the public identifier "-//Norman
Walsh//DTDDocBk XMLV3.1.4//EN" and the
systemidentifier"http://nwalsh.com/docbook/xml/3.1.4/db3xml.dtd", and if
theseentities havebeen installed on your system and the catalogs actually
point tothem, libxmlwill fetch them from the local disk.
Note: Really don't usethisDOCTYPE
example it's a really old version, but is fine as an example.
Libxml2 will check the catalog each time that it is requested to
loadanentity, this includes DTD, external parsed entities, stylesheets, etc
...Ifyour system is correctly configured all the authoring phase
andprocessingshould use only local files, even if your document stays
portablebecause ituses the canonical public and system ID, referencing the
remotedocument.
Here is a couple of fragments from XML Catalogs used in
libxml2earlyregression tests in test/catalogs:
<?xml version="1.0"?>
<!DOCTYPE catalog PUBLIC
"-//OASIS//DTD Entity Resolution XML Catalog V1.0//EN"
"http://www.oasis-open.org/committees/entity/release/1.0/catalog.dtd">
<catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog">
<public publicId="-//OASIS//DTD DocBook XML V4.1.2//EN"
uri="http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd"/>
...
This is the beginning of a catalog for DocBook 4.1.2, XML
Catalogsarewritten in XML, there is a specific namespace for
catalogelements"urn:oasis:names:tc:entity:xmlns:xml:catalog". The first entry
inthiscatalog is a publicmapping it allows to associate
aPublicIdentifier with an URI.
...
<rewriteSystem systemIdStartString="http://www.oasis-open.org/docbook/"
rewritePrefix="file:///usr/share/xml/docbook/"/>
...
A rewriteSystemis a very powerful instruction, it saysthatany
URI starting with a given prefix should be looked at anotherURIconstructed by
replacing the prefix with an new one. In effect this actslikea cache system
for a full area of the Web. In practice it is extremelyusefulwith a file
prefix if you have installed a copy of those resources onyourlocal system.
...
<delegatePublic publicIdStartString="-//OASIS//DTD XML Catalog //"
catalog="file:///usr/share/xml/docbook.xml"/>
<delegatePublic publicIdStartString="-//OASIS//ENTITIES DocBook XML"
catalog="file:///usr/share/xml/docbook.xml"/>
<delegatePublic publicIdStartString="-//OASIS//DTD DocBook XML"
catalog="file:///usr/share/xml/docbook.xml"/>
<delegateSystem systemIdStartString="http://www.oasis-open.org/docbook/"
catalog="file:///usr/share/xml/docbook.xml"/>
<delegateURI uriStartString="http://www.oasis-open.org/docbook/"
catalog="file:///usr/share/xml/docbook.xml"/>
...
Delegation is the core features which allows to build a tree
ofcatalogs,easier to maintain than a single catalog, based on
PublicIdentifier, SystemIdentifier or URI prefixes it instructs the
catalogsoftware to look upentries in another resource. This feature allow to
buildhierarchies ofcatalogs, the set of entries presented should be
sufficient toredirect theresolution of all DocBook references to the specific
catalogin/usr/share/xml/docbook.xmlthis one in turn could
delegateallreferences for DocBook 4.2.1 to a specific catalog installed at
the sametimeas the DocBook resources on the local machine.
The user can change the default catalog behaviour by redirecting
queriestoits own set of catalogs, this can be done by
settingtheXML_CATALOG_FILESenvironment variable to a list of
catalogs,anempty one should deactivate loading the
default/etc/xml/catalogdefault catalog
Setting up the XML_DEBUG_CATALOGenvironment variable
willmakelibxml2 output debugging informations for each catalog
operations,forexample:
orchis:~/XML -> xmllint --memory --noout test/ent2
warning: failed to load external entity "title.xml"
orchis:~/XML -> export XML_DEBUG_CATALOG=
orchis:~/XML -> xmllint --memory --noout test/ent2
Failed to parse catalog /etc/xml/catalog
Failed to parse catalog /etc/xml/catalog
warning: failed to load external entity "title.xml"
Catalogs cleanup
orchis:~/XML ->
The test/ent2 references an entity, running the parser from memorymakesthe
base URI unavailable and the the "title.xml" entity cannot beloaded.Setting
up the debug environment variable allows to detect that anattempt ismade to
load the /etc/xml/catalogbut since it's notpresent theresolution
fails.
But the most advanced way to debug XML catalog processing is to
usethexmlcatalogcommand shipped with libxml2, it allows
toloadcatalogs and make resolution queries to see what is going on. This
isalsoused for the regression tests:
orchis:~/XML -> ./xmlcatalog test/catalogs/docbook.xml \
"-//OASIS//DTD DocBook XML V4.1.2//EN"
http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd
orchis:~/XML ->
For debugging what is going on, adding one -v flags increase
theverbositylevel to indicate the processing done (adding a second flag
alsoindicatewhat elements are recognized at parsing):
orchis:~/XML -> ./xmlcatalog -v test/catalogs/docbook.xml \
"-//OASIS//DTD DocBook XML V4.1.2//EN"
Parsing catalog test/catalogs/docbook.xml's content
Found public match -//OASIS//DTD DocBook XML V4.1.2//EN
http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd
Catalogs cleanup
orchis:~/XML ->
A shell interface is also available to debug and process
multiplequeries(and for regression tests):
orchis:~/XML -> ./xmlcatalog -shell test/catalogs/docbook.xml \
"-//OASIS//DTD DocBook XML V4.1.2//EN"
> help
Commands available:
public PublicID: make a PUBLIC identifier lookup
system SystemID: make a SYSTEM identifier lookup
resolve PublicID SystemID: do a full resolver lookup
add 'type' 'orig' 'replace' : add an entry
del 'values' : remove values
dump: print the current catalog state
debug: increase the verbosity level
quiet: decrease the verbosity level
exit: quit the shell
> public "-//OASIS//DTD DocBook XML V4.1.2//EN"
http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd
> quit
orchis:~/XML ->
This should be sufficient for most debugging purpose, this wasactuallyused
heavily to debug the XML Catalog implementation itself.
Basically XML Catalogs are XML files, you can either use XML toolstomanage
them or use xmlcatalogfor this. The basic stepisto create a
catalog the -create option provide this facility:
orchis:~/XML -> ./xmlcatalog --create tst.xml
<?xml version="1.0"?>
<!DOCTYPE catalog PUBLIC "-//OASIS//DTD Entity Resolution XML Catalog V1.0//EN"
"http://www.oasis-open.org/committees/entity/release/1.0/catalog.dtd">
<catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog"/>
orchis:~/XML ->
By default xmlcatalog does not overwrite the original catalog and
savetheresult on the standard output, this can be overridden using
the-nooutoption. The -addcommand allows to add entries
inthecatalog:
orchis:~/XML -> ./xmlcatalog --noout --create --add "public" \
"-//OASIS//DTD DocBook XML V4.1.2//EN" \
http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd tst.xml
orchis:~/XML -> cat tst.xml
<?xml version="1.0"?>
<!DOCTYPE catalog PUBLIC "-//OASIS//DTD Entity Resolution XML Catalog V1.0//EN" \
"http://www.oasis-open.org/committees/entity/release/1.0/catalog.dtd">
<catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog">
<public publicId="-//OASIS//DTD DocBook XML V4.1.2//EN"
uri="http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd"/>
</catalog>
orchis:~/XML ->
The -addoption will always take 3 parameters even if
someofthe XML Catalog constructs (like nextCatalog) will have only
asingleargument, just pass a third empty string, it will be ignored.
Similarly the -deloption remove matching entries
fromthecatalog:
orchis:~/XML -> ./xmlcatalog --del \
"http://www.oasis-open.org/docbook/xml/4.1.2/docbookx.dtd" tst.xml
<?xml version="1.0"?>
<!DOCTYPE catalog PUBLIC "-//OASIS//DTD Entity Resolution XML Catalog V1.0//EN"
"http://www.oasis-open.org/committees/entity/release/1.0/catalog.dtd">
<catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog"/>
orchis:~/XML ->
The catalog is now empty. Note that the matching
of-delisexact and would have worked in a similar fashion with
thePublic IDstring.
This is rudimentary but should be sufficient to manage a not
toocomplexcatalog tree of resources.
First, and like for every other module of libxml, there is
anautomaticallygenerated API page
forcatalogsupport.
The header for the catalog interfaces should be included as:
#include <libxml/catalog.h>
The API is voluntarily kept very simple. First it is not
obviousthatapplications really need access to it since it is the default
behaviouroflibxml2 (Note: it is possible to completely override libxml2
defaultcatalogby using xmlSetExternalEntityLoadertoplug
anapplication specific resolver).
Basically libxml2 support 2 catalog lists:
- the default one, global shared by all the application
- a per-document catalog, this one is built if the document
usesthe
oasis-xml-catalogPIs to specify its own catalog list,
itisassociated to the parser context and destroyed when the
parsingcontextis destroyed.
the document one will be used first if it exists.
Initialization routines:
xmlInitializeCatalog(), xmlLoadCatalog() and xmlLoadCatalogs()
shouldbeused at startup to initialize the catalog, if the catalog
shouldbeinitialized with specific values xmlLoadCatalog()
orxmlLoadCatalogs()should be called before xmlInitializeCatalog() which
wouldotherwise do adefault initialization first.
The xmlCatalogAddLocal() call is used by the parser to grow thedocumentown
catalog list if needed.
Preferences setup:
The XML Catalog spec requires the possibility to select
defaultpreferencesbetween public and system
delegation,xmlCatalogSetDefaultPrefer() allowsthis, xmlCatalogSetDefaults()
andxmlCatalogGetDefaults() allow to control ifXML Catalogs resolution
shouldbe forbidden, allowed for global catalog, fordocument catalog or both,
thedefault is to allow both.
And of course xmlCatalogSetDebug() allows to generate
debugmessages(through the xmlGenericError() mechanism).
Querying routines:
xmlCatalogResolve(),
xmlCatalogResolveSystem(),xmlCatalogResolvePublic()and xmlCatalogResolveURI()
are relatively explicitif you read the XMLCatalog specification they
correspond to section 7algorithms, they shouldalso work if you have loaded an
SGML catalog with asimplified semantic.
xmlCatalogLocalResolve() and xmlCatalogLocalResolveURI() are the
samebutoperate on the document catalog list
Cleanup and Miscellaneous:
xmlCatalogCleanup() free-up the global catalog, xmlCatalogFreeLocal()isthe
per-document equivalent.
xmlCatalogAdd() and xmlCatalogRemove() are used to dynamically
modifythefirst catalog in the global list, and xmlCatalogDump() allows to
dumpacatalog state, those routines are primarily designed for xmlcatalog,
I'mnotsure that exposing more complex interfaces (like navigation ones)
wouldbereally useful.
The xmlParseCatalogFile() is a function used to load XML Catalogfiles,it's
similar as xmlParseFile() except it bypass all catalog lookups,it'sprovided
because this functionality may be useful for client tools.
threaded environments:
Since the catalog tree is built progressively, some care has been
takentotry to avoid troubles in multithreaded environments. The code is
nowthreadsafe assuming that the libxml2 library has been compiled
withthreadssupport.
The XML Catalog specification is relatively recent so there
isn'tmuchliterature to point at:
If you have suggestions for corrections or additions, simply contactme:
This section is directly intended to help programmers
gettingbootstrappedusing the XML tollkit from the C language. It is not
intended tobeextensive. I hope the automatically generated documents will
providethecompleteness required, but as a separate set of documents. The
interfacesofthe XML parser are by principle low level, Those interested in a
higherlevelAPI should look at DOM.
The parser interfaces
forXMLareseparated from the HTMLparserinterfaces. Let's have a
look at how the XML parser can becalled:
Usually, the first thing to do is to read an XML input. The
parseracceptsdocuments either from in-memory strings or from files. The
functionsaredefined in "parser.h":
xmlDocPtr xmlParseMemory(char *buffer, int size);Parse a null-terminated string containing the document.
xmlDocPtr xmlParseFile(const char *filename);Parse an XML document contained in a (possibly compressed)file.
The parser returns a pointer to the document structure (or NULL in
caseoffailure).
Invoking the parser: the push method
In order for the application to keep the control when the document
isbeingfetched (which is common for GUI based programs) libxml2 provides
apushinterface, too, as of version 1.8.3. Here are the interfacefunctions:
xmlParserCtxtPtr xmlCreatePushParserCtxt(xmlSAXHandlerPtr sax,
void *user_data,
const char *chunk,
int size,
const char *filename);
int xmlParseChunk (xmlParserCtxtPtr ctxt,
const char *chunk,
int size,
int terminate);
and here is a simple example showing how to use the interface:
FILE *f;
f = fopen(filename, "r");
if (f != NULL) {
int res, size = 1024;
char chars[1024];
xmlParserCtxtPtr ctxt;
res = fread(chars, 1, 4, f);
if (res > 0) {
ctxt = xmlCreatePushParserCtxt(NULL, NULL,
chars, res, filename);
while ((res = fread(chars, 1, size, f)) > 0) {
xmlParseChunk(ctxt, chars, res, 0);
}
xmlParseChunk(ctxt, chars, 0, 1);
doc = ctxt->myDoc;
xmlFreeParserCtxt(ctxt);
}
}
The HTML parser embedded into libxml2 also has a push
interface;thefunctions are just prefixed by "html" rather than "xml".
Invoking the parser: the SAX interface
The tree-building interface makes the parser memory-hungry,
firstloadingthe document in memory and then building the tree itself. Reading
adocumentwithout building the tree is possible using the SAX interfaces
(seeSAX.h andJamesHenstridge'sdocumentation).
Note also that the push interface can belimited to SAX:just use the two first
arguments ofxmlCreatePushParserCtxt().
The other way to get an XML tree in memory is by building
it.Basicallythere is a set of functions dedicated to building new
elements.(These arealso described in <libxml/tree.h>.) For example,
here is apiece ofcode that produces the XML document used in the previous
examples:
#include <libxml/tree.h>
xmlDocPtr doc;
xmlNodePtr tree, subtree;
doc = xmlNewDoc("1.0");
doc->children = xmlNewDocNode(doc, NULL, "EXAMPLE", NULL);
xmlSetProp(doc->children, "prop1", "gnome is great");
xmlSetProp(doc->children, "prop2", "& linux too");
tree = xmlNewChild(doc->children, NULL, "head", NULL);
subtree = xmlNewChild(tree, NULL, "title", "Welcome to Gnome");
tree = xmlNewChild(doc->children, NULL, "chapter", NULL);
subtree = xmlNewChild(tree, NULL, "title", "The Linux adventure");
subtree = xmlNewChild(tree, NULL, "p", "bla bla bla ...");
subtree = xmlNewChild(tree, NULL, "image", NULL);
xmlSetProp(subtree, "href", "linus.gif");
Not really rocket science ...
Basically by including"tree.h"yourcode
has access to the internal structure of all the elementsof the tree.The names
should be somewhat simple
likeparent,children,
next,prev,properties,
etc... For example, stillwith the previousexample:
doc->children->children->children
points to the title element,
doc->children->children->next->children->children
points to the text node containing the chapter title
"TheLinuxadventure".
NOTE: XML allows PIs and
commentstobepresent before the document root, so
doc->childrenmaypointto an element which is not the document
Root Element; afunctionxmlDocGetRootElement()was added for this
purpose.
Functions are provided for reading and writing the document content.Hereis
an excerpt from the tree API:
xmlAttrPtr xmlSetProp(xmlNodePtr node, const xmlChar
*name,constxmlChar *value);This sets (or changes) an attribute carried by an ELEMENT
node.Thevalue can be NULL.
const xmlChar *xmlGetProp(xmlNodePtr node,
constxmlChar*name);This function returns a pointer to new copy of thepropertycontent.
Note that the user must deallocate the result.
Two functions are provided for reading and writing the text
associatedwithelements:
xmlNodePtr xmlStringGetNodeList(xmlDocPtr doc,
constxmlChar*value);This function takes an "external" string and converts it toonetext
node or possibly to a list of entity and text nodes.Allnon-predefined
entity references like &Gnome; will bestoredinternally as entity
nodes, hence the result of the function maynot bea single node.
xmlChar *xmlNodeListGetString(xmlDocPtr doc, xmlNodePtr
list,intinLine);This function is the inverseofxmlStringGetNodeList().
It generates a newstringcontaining the content of the text and entity
nodes. Note theextraargument inLine. If this argument is set to 1, the
function willexpandentity references. For example, instead of
returning the&Gnome;XML encoding in the string, it will substitute
it with itsvalue (say,"GNU Network Object Model Environment").
Basically 3 options are possible:
void xmlDocDumpMemory(xmlDocPtr cur,
xmlChar**mem,int*size);Returns a buffer into which the document has been saved.
extern void xmlDocDump(FILE *f, xmlDocPtr doc);Dumps a document to an open file descriptor.
int xmlSaveFile(const char *filename, xmlDocPtr cur);Saves the document to a file. In this case,
thecompressioninterface is triggered if it has been turned on.
The library transparently handles compression when
doingfile-basedaccesses. The level of compression on saves can be turned on
eithergloballyor individually for one file:
int xmlGetDocCompressMode (xmlDocPtr doc);Gets the document compression ratio (0-9).
void xmlSetDocCompressMode (xmlDocPtr doc, int mode);Sets the document compression ratio.
int xmlGetCompressMode(void);Gets the default compression ratio.
void xmlSetCompressMode(int mode);Sets the default compression ratio.
Entities in principle are similar to simple C macros. An entity
definesanabbreviation for a given string that you can reuse many times
throughoutthecontent of your document. Entities are especially useful when a
givenstringmay occur frequently within a document, or to confine the change
neededto adocument to a restricted area in the internal subset of the
document (atthebeginning). Example:
1 <?xml version="1.0"?>
2 <!DOCTYPE EXAMPLE SYSTEM "example.dtd" [
3 <!ENTITY xml "Extensible Markup Language">
4 ]>
5 <EXAMPLE>
6 &xml;
7 </EXAMPLE>
Line 3 declares the xml entity. Line 6 uses the xml entity, byprefixingits
name with '&' and following it by ';' without any spacesadded. Thereare 5
predefined entities in libxml2 allowing you to escapecharacters
withpredefined meaning in some parts of the xml
documentcontent:<for the character
'<',>for the character
'>','for the
character''',"for the character
'"',and&for the character '&'.
One of the problems related to entities is that you may want the
parsertosubstitute an entity's content so that you can see the replacement
textinyour application. Or you may prefer to keep entity references as such
inthecontent to be able to save the document back without losing
thisusuallyprecious information (if the user went through the pain
ofexplicitlydefining entities, he may have a a rather negative attitude if
youblindlysubstitute them as saving time). The xmlSubstituteEntitiesDefault()functionallows
you to check and change the behaviour, which is to notsubstituteentities by
default.
Here is the DOM tree built by libxml2 for the previous document
inthedefault case:
/gnome/src/gnome-xml -> ./xmllint --debug test/ent1
DOCUMENT
version=1.0
ELEMENT EXAMPLE
TEXT
content=
ENTITY_REF
INTERNAL_GENERAL_ENTITY xml
content=Extensible Markup Language
TEXT
content=
And here is the result when substituting entities:
/gnome/src/gnome-xml -> ./tester --debug --noent test/ent1
DOCUMENT
version=1.0
ELEMENT EXAMPLE
TEXT
content= Extensible Markup Language
So, entities or no entities? Basically, it depends on your use
case.Isuggest that you keep the non-substituting default behaviour and
avoidusingentities in your XML document or data if you are not willing to
handletheentity references elements in the DOM tree.
Note that at save time libxml2 enforces the conversion of
thepredefinedentities where necessary to prevent well-formedness problems,
andwill alsotransparently replace those with chars (i.e. it will not
generateentityreference elements in the DOM tree or call the reference() SAX
callbackwhenfinding them in the input).
WARNING: handlingentitieson
top of the libxml2 SAX interface is difficult!!! If you plan
tousenon-predefined entities in your documents, then the learning curve
tohandlethen using the SAX API may be long. If you plan to use
complexdocuments, Istrongly suggest you consider using the DOM interface
instead andlet libxmldeal with the complexity rather than trying to do it
yourself.
The libxml2 library implements XML
namespacessupportbyrecognizing namespace constructs in the input, and
does namespacelookupautomatically when building the DOM tree. A namespace
declarationisassociated with an in-memory structure and all elements or
attributeswithinthat namespace point to it. Hence testing the namespace is a
simple andfastequality operation at the user level.
I suggest that people using libxml2 use a namespace, and declare it
intheroot element of their document as the default namespace. Then they
don'tneedto use the prefix in the content but we will have a basis for
futuresemanticrefinement and merging of data from different sources. This
doesn'tincreasethe size of the XML output significantly, but significantly
increasesitsvalue in the long-term. Example:
<mydoc xmlns="http://mydoc.example.org/schemas/">
<elem1>...</elem1>
<elem2>...</elem2>
</mydoc>
The namespace value has to be an absolute URL, but the URL doesn't
havetopoint to any existing resource on the Web. It will bind all the
elementandattributes with that URL. I suggest to use an URL within a
domainyoucontrol, and that the URL should contain some kind of version
informationifpossible. For example,
"http://www.gnome.org/gnumeric/1.0/"isagood namespace scheme.
Then when you load a file, make sure that a namespace
carryingtheversion-independent prefix is installed on the root element of
yourdocument,and if the version information don't match something you know,
warnthe userand be liberal in what you accept as the input. Also do *not* try
tobasenamespace checking on the prefix value. <foo:text> may be
exactlythesame as <bar:text> in another document. What really matters
is theURIassociated with the element or the attribute, not the prefix string
(whichisjust a shortcut for the full URI). In libxml, element and attributes
haveannsfield pointing to an xmlNs structure detailing
thenamespaceprefix and its URI.
@@Interfaces@@
xmlNodePtr node;
if(!strncmp(node->name,"mytag",5)
&& node->ns
&& !strcmp(node->ns->href,"http://www.mysite.com/myns/1.0")) {
...
}
Usually people object to using namespaces together with validitychecking.I
will try to make sure that using namespaces won't break validitychecking,so
even if you plan to use or currently are using validation Istronglysuggest
adding namespaces to your document. A default
namespaceschemexmlns="http://...."should not break validity even
onlessflexible parsers. Using namespaces to mix and differentiate
contentcomingfrom multiple DTDs will certainly break current validation
schemes. Tochecksuch documents one needs to use schema-validation, which is
supportedinlibxml2 as well. See relagx-ngand w3c-schema.
Incompatible changes:
Version 2 of libxml2 is the first version introducing
seriousbackwardincompatible changes. The main goals were:
- a general cleanup. A number of mistakes inherited from the
veryearlyversions couldn't be changed due to compatibility
constraints.Examplethe "childs" element in the nodes.
- Uniformization of the various nodes, at least for their header
andlinkparts (doc, parent, children, prev, next), the goal is
asimplerprogramming model and simplifying the task of the
DOMimplementors.
- better conformances to the XML specification, for example version1.xhad
an heuristic to try to detect ignorable white spaces. As a resulttheSAX
event generated were ignorableWhitespace() while the
specrequirescharacter() in that case. This also mean that a number of
DOMnodecontaining blank text may populate the DOM tree which were
notpresentbefore.
How to fix libxml-1.x code:
So client code of libxml designed to run with version 1.x may have
tobechanged to compile against version 2.x of libxml. Here is a list
ofchangesthat I have collected, they may not be sufficient, so in case you
findotherchange which are required, dropme amail:
- The package name have changed from libxml to libxml2, the librarynameis
now -lxml2 . There is a new xml2-config script which should beused
toselect the right parameters libxml2
- Node childsfield has
beenrenamedchildrenso s/childs/children/g should
beapplied(probability of having "childs" anywhere else is close to 0+
- The document don't have anymore a rootelement
ithasbeen replaced by childrenand usually you will
getalist of element here. For example a Dtd element for the
internalsubsetand it's declaration may be found in that list, as well
asprocessinginstructions or comments found before or after the
documentroot element.Use xmlDocGetRootElement(doc)to get
theroot element ofa document. Alternatively if you are sure to not
referenceDTDs nor havePIs or comments before or after the
rootelements/->root/->children/g will probably do it.
- The white space issue, this one is more complex, unless special
caseofvalidating parsing, the line breaks and spaces usually used
forindentingand formatting the document content becomes significant. So
theyarereported by SAX and if your using the DOM tree, corresponding
nodesaregenerated. Too approach can be taken:
- lazy one, use the
compatibilitycallxmlKeepBlanksDefault(0)but be aware
that youarerelying on a special (and possibly broken) set of
heuristicsoflibxml to detect ignorable blanks. Don't complain if it
breaksormake your application not 100% clean w.r.t. to it's
input.
- the Right Way: change you code to accept
possiblyinsignificantblanks characters, or have your tree populated
withweird blank textnodes. You can spot them using the
commodityfunctionxmlIsBlankNode(node)returning 1 for
suchblanknodes.
Note also that with the new default the output functions don't
addanyextra indentation when saving a tree in order to be able to
roundtrip(read and save) without inflating the document with
extraformattingchars.
- The include path has changed to $prefix/libxml/ and
theincludesthemselves uses this new prefix in includes instructions...
Ifyou areusing (as expected) the
xml2-config --cflags
output to generate you compile commands this will probably work
outofthe box
- xmlDetectCharEncoding takes an extra argument indicating the
lengthinbyte of the head of the document available for character
detection.
Ensuring both libxml-1.x and libxml-2.x compatibility
Two new version of libxml (1.8.11) and libxml2 (2.3.4) have beenreleasedto
allow smooth upgrade of existing libxml v1code whileretainingcompatibility.
They offers the following:
- similar include naming, one
shoulduse#include<libxml/...>in both cases.
- similar identifiers defined via macros for the child and
rootfields:respectivelyxmlChildrenNodeandxmlRootNode
- a new macro LIBXML_TEST_VERSIONwhich should
beinsertedonce in the client code
So the roadmap to upgrade your existing libxml applications
isthefollowing:
- install the libxml-1.8.8 (and libxml-devel-1.8.8) packages
- find all occurrences where the xmlDoc rootfield
isusedand change it to xmlRootNode
- similarly find all occurrences where
thexmlNodechildsfield is used and change
ittoxmlChildrenNode
- add a LIBXML_TEST_VERSIONmacro somewhere
inyourmain()or in the library init entry point
- Recompile, check compatibility, it should still work
- Change your configure script to look first for xml2-config and
fallbackusing xml-config . Use the --cflags and --libs output of the
commandasthe Include and Linking parameters needed to use libxml.
- install libxml2-2.3.x and libxml2-devel-2.3.x
(libxml-1.8.yandlibxml-devel-1.8.y can be kept simultaneously)
- remove your config.cache, relaunch your configuration
mechanism,andrecompile, if steps 2 and 3 were done right it should
compileas-is
- Test that your application is still running correctly, if not thismaybe
due to extra empty nodes due to formating spaces being kept
inlibxml2contrary to libxml1, in that case insert
xmlKeepBlanksDefault(1)in yourcode before calling the parser
(nexttoLIBXML_TEST_VERSIONis a fine place).
Following those steps should work. It worked for some of my own code.
Let me put some emphasis on the fact that there is far more
changesfromlibxml 1.x to 2.x than the ones you may have to patch for. The
overallcodehas been considerably cleaned up and the conformance to the
XMLspecificationhas been drastically improved too. Don't take those changes
asan excuse tonot upgrade, it may cost a lot on the long term ...
Starting with 2.4.7, libxml2 makes provisions to ensure
thatconcurrentthreads can safely work in parallel parsing different
documents.There ishowever a couple of things to do to ensure it:
- configure the library accordingly using the --with-threads options
- call xmlInitParser() in the "main" thread before using any ofthelibxml2
API (except possibly selecting a different memoryallocator)
Note that the thread safety cannot be ensured for multiple
threadssharingthe same document, the locking must be done at the application
level,libxmlexports a basic mutex and reentrant mutexes API
in<libxml/threads.h>.The parts of the library checked for thread
safetyare:
- concurrent loading
- file access resolution
- catalog access
- catalog building
- entities lookup/accesses
- validation
- global variables per-thread override
- memory handling
XPath is supposed to be thread safe now, but this
wasn'ttestedseriously.
DOMstands for the
DocumentObjectModel; this is an API for accessing XML or HTML
structureddocuments.Native support for DOM in Gnome is on the way (module
gnome-dom),and will bebased on gnome-xml. This will be a far cleaner
interface tomanipulate XMLfiles within Gnome since it won't expose the
internalstructure.
The current DOM implementation on top of libxml2 is the gdome2 Gnome module,thisis
a full DOM interface, thanks to Paolo Casarini, check the Gdome2
homepageformoreinformations.
Here is a real size example, where the actual content of
theapplicationdata is not kept in the DOM tree but uses internal structures.
Itis based ona proposal to keep a database of jobs related to Gnome, with
anXML basedstorage structure. Here is an XML
encodedjobsbase:
<?xml version="1.0"?>
<gjob:Helping xmlns:gjob="http://www.gnome.org/some-location">
<gjob:Jobs>
<gjob:Job>
<gjob:Project ID="3"/>
<gjob:Application>GBackup</gjob:Application>
<gjob:Category>Development</gjob:Category>
<gjob:Update>
<gjob:Status>Open</gjob:Status>
<gjob:Modified>Mon, 07 Jun 1999 20:27:45 -0400 MET DST</gjob:Modified>
<gjob:Salary>USD 0.00</gjob:Salary>
</gjob:Update>
<gjob:Developers>
<gjob:Developer>
</gjob:Developer>
</gjob:Developers>
<gjob:Contact>
<gjob:Person>Nathan Clemons</gjob:Person>
<gjob:Email>nathan@windsofstorm.net</gjob:Email>
<gjob:Company>
</gjob:Company>
<gjob:Organisation>
</gjob:Organisation>
<gjob:Webpage>
</gjob:Webpage>
<gjob:Snailmail>
</gjob:Snailmail>
<gjob:Phone>
</gjob:Phone>
</gjob:Contact>
<gjob:Requirements>
The program should be released as free software, under the GPL.
</gjob:Requirements>
<gjob:Skills>
</gjob:Skills>
<gjob:Details>
A GNOME based system that will allow a superuser to configure
compressed and uncompressed files and/or file systems to be backed
up with a supported media in the system. This should be able to
perform via find commands generating a list of files that are passed
to tar, dd, cpio, cp, gzip, etc., to be directed to the tape machine
or via operations performed on the filesystem itself. Email
notification and GUI status display very important.
</gjob:Details>
</gjob:Job>
</gjob:Jobs>
</gjob:Helping>
While loading the XML file into an internal DOM tree is a matter
ofcallingonly a couple of functions, browsing the tree to gather the data
andgeneratethe internal structures is harder, and more error prone.
The suggested principle is to be tolerant with respect to
theinputstructure. For example, the ordering of the attributes is
notsignificant,the XML specification is clear about it. It's also usually a
goodidea not todepend on the order of the children of a given node, unless
itreally makesthings harder. Here is some code to parse the information for
aperson:
/*
* A person record
*/
typedef struct person {
char *name;
char *email;
char *company;
char *organisation;
char *smail;
char *webPage;
char *phone;
} person, *personPtr;
/*
* And the code needed to parse it
*/
personPtr parsePerson(xmlDocPtr doc, xmlNsPtr ns, xmlNodePtr cur) {
personPtr ret = NULL;
DEBUG("parsePerson\n");
/*
* allocate the struct
*/
ret = (personPtr) malloc(sizeof(person));
if (ret == NULL) {
fprintf(stderr,"out of memory\n");
return(NULL);
}
memset(ret, 0, sizeof(person));
/* We don't care what the top level element name is */
cur = cur->xmlChildrenNode;
while (cur != NULL) {
if ((!strcmp(cur->name, "Person")) && (cur->ns == ns))
ret->name = xmlNodeListGetString(doc, cur->xmlChildrenNode, 1);
if ((!strcmp(cur->name, "Email")) && (cur->ns == ns))
ret->email = xmlNodeListGetString(doc, cur->xmlChildrenNode, 1);
cur = cur->next;
}
return(ret);
}
Here are a couple of things to notice:
- Usually a recursive parsing style is the more convenient one: XMLdatais
by nature subject to repetitive constructs and usually
exhibitshighlystructured patterns.
- The two arguments of type xmlDocPtrand
xmlNsPtr,i.e.the pointer to the global XML document and the
namespace reserved totheapplication. Document wide information are needed
for example todecodeentities and it's a good coding practice to define a
namespace foryourapplication set of data and test that the element and
attributesyou'reanalyzing actually pertains to your application space.
This isdone by asimple equality test (cur->ns == ns).
- To retrieve text and attributes value, you can use
thefunctionxmlNodeListGetStringto gather all the text and
entityreferencenodes generated by the DOM output and produce an single
textstring.
Here is another piece of code used to parse another level
ofthestructure:
#include <libxml/tree.h>
/*
* a Description for a Job
*/
typedef struct job {
char *projectID;
char *application;
char *category;
personPtr contact;
int nbDevelopers;
personPtr developers[100]; /* using dynamic alloc is left as an exercise */
} job, *jobPtr;
/*
* And the code needed to parse it
*/
jobPtr parseJob(xmlDocPtr doc, xmlNsPtr ns, xmlNodePtr cur) {
jobPtr ret = NULL;
DEBUG("parseJob\n");
/*
* allocate the struct
*/
ret = (jobPtr) malloc(sizeof(job));
if (ret == NULL) {
fprintf(stderr,"out of memory\n");
return(NULL);
}
memset(ret, 0, sizeof(job));
/* We don't care what the top level element name is */
cur = cur->xmlChildrenNode;
while (cur != NULL) {
if ((!strcmp(cur->name, "Project")) && (cur->ns == ns)) {
ret->projectID = xmlGetProp(cur, "ID");
if (ret->projectID == NULL) {
fprintf(stderr, "Project has no ID\n");
}
}
if ((!strcmp(cur->name, "Application")) && (cur->ns == ns))
ret->application = xmlNodeListGetString(doc, cur->xmlChildrenNode, 1);
if ((!strcmp(cur->name, "Category")) && (cur->ns == ns))
ret->category = xmlNodeListGetString(doc, cur->xmlChildrenNode, 1);
if ((!strcmp(cur->name, "Contact")) && (cur->ns == ns))
ret->contact = parsePerson(doc, ns, cur);
cur = cur->next;
}
return(ret);
}
Once you are used to it, writing this kind of code is quite
simple,butboring. Ultimately, it could be possible to write stubbers taking
eitherCdata structure definitions, a set of XML examples or an XML DTD
andproducethe code needed to import and export the content between C data
andXMLstorage. This is left as an exercise to the reader :-)
Feel free to use the code for the
fullCparsing exampleas a template, it is also available with Makefile
intheGnome CVS base under gnome-xml/example